This document complements the paper "Developing Process Scheduling Policies in User Space with Common OS Features" presented at 15th ACM SIGOPS Asia-Pacific Workshop on Systems (APSys 2024).
WARNING: The authors will not bear any responsibility if the implementations, provided by the authors, cause any problems.
- Paper: https://dl.acm.org/doi/10.1145/3678015.3680481
- Slides: https://yasukata.github.io/presentation/2024/09/apsys2024/apsys24_slides_yasukata.pdf
- Networked server implementation used in the experiments
- Benchmark program: https://github.com/yasukata/bench-iip
- TCP/IP stack: https://github.com/yasukata/iip
The following loop.c is to make it easy to monitor the behavior of a process.
click here to show loop.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <assert.h>
int main(int argc, char const* argv[])
{
if (argc == 2) {
unsigned int cnt = atoi(argv[1]), pos = 0, fwd = 1;
assert(cnt > 0);
while (1) {
printf("\rpid %d |%.*s=%.*s|",
getpid(),
pos % 20, " ",
19 - pos % 20, " ");
fflush(stdout);
if (fwd) {
pos++;
if (pos == 19)
fwd = 0;
} else {
pos--;
if (pos == 0)
fwd = 1;
}
for (volatile unsigned int i = 0; i < cnt; i++) ;
}
} else
printf("please specify a number\n");
return 0;
}Once you save the program above as a file named loop.c, you can compile it by the following command and it will generate loop.
gcc loop.c -o loop
The generated binary can be run by the following command. Supposedly, a bar = goes back and forth. The specified number 100000000 is a configuratin parameter for tuning the speed of the bar, and the bar moves slower if you increase this value.
./loop 100000000
The following trick.sh implements a round-robin scheduling policy.
click here to show trick.sh
#!/bin/bash
CPU_CORE_MASK=$((1<<$1)) # 1st argument
SCHED_PERIOD=$2 # 2nd argument
NORMAL_PROCESS_PID_0=$3 # 3rd argument
NORMAL_PROCESS_PID_1=$4 # 4th argument
SCHED_PROCESS_PID=$$ # process running this script
# priority values used in this example
PRIORITY_HIGH=3; PRIORITY_MIDDLE=2; PRIORITY_LOW=1;
# chrt internally executes sched_setscheduler:
# set SCHED_FIFO + high priority to scheduler process
chrt -f -p $PRIORITY_HIGH $SCHED_PROCESS_PID
# taskset internally executes sched_setaffinity:
# pin scheduler process to the user-specified CPU core
taskset -p $CPU_CORE_MASK $SCHED_PROCESS_PID
# set SCHED_FIFO + low priority to normal processes
# pin normal processes to the user-specified CPU core
chrt -f -p $PRIORITY_LOW $NORMAL_PROCESS_PID_0
taskset -p $CPU_CORE_MASK $NORMAL_PROCESS_PID_0
chrt -f -p $PRIORITY_LOW $NORMAL_PROCESS_PID_1
taskset -p $CPU_CORE_MASK $NORMAL_PROCESS_PID_1
# temporary variable setting
prev=$NORMAL_PROCESS_PID_1
# primary loop of scheduler process
while [ 1 ]; do
# pick up next in a round-robin manner
if [ $prev -eq $NORMAL_PROCESS_PID_0 ]; then
next=$NORMAL_PROCESS_PID_1
else
next=$NORMAL_PROCESS_PID_0
fi
# elevate priority of next to middle
chrt -f -p $PRIORITY_MIDDLE $next
# lower priority of prev to low
chrt -f -p $PRIORITY_LOW $prev
# enter sleep to switch to normal process
sleep $SCHED_PERIOD
# update variable
prev=$next
doneOnce the program above is saved as trick.sh, please type the following to make it executable.
chmod +x ./trick.sh
The arguments of trick.sh is as follows.
- 1st argument: CPU core where the scheduler and two normal processes run
- 2nd argument: interval for switching the two normal processes (in second)
- 3rd argument: pid of a normal process
- 4th argument: pid of a normal process
To try the programs above, please open three terminals/consoles and please type the commands below.
Terminal/console 1
$ ./loop 100000000
pid 1522 | = |
Terminal/console 2
$ ./loop 100000000
pid 1523 | = |
Terminal/console 3
- Please change the number 1522 1523 according to the outputs from terminal/console 1 and 2
- The following runs the programs on CPU core 1 as specified 1 for the 1st argument; if you wish to use another CPU core, please change the value for the 1st argument
sudo ./trick.sh 1 5 1522 1523
Supposedly, while the bar on terminal/console 1 is moving, the bar on terminal/console 2 freezes, and a switching happens every 5 seconds.
Here, we observe these two normal processes are switched every 5 seconds by the scheduler process.
The following shows how trick.sh manipulates the priorities of the normal processes and switch them periodically.
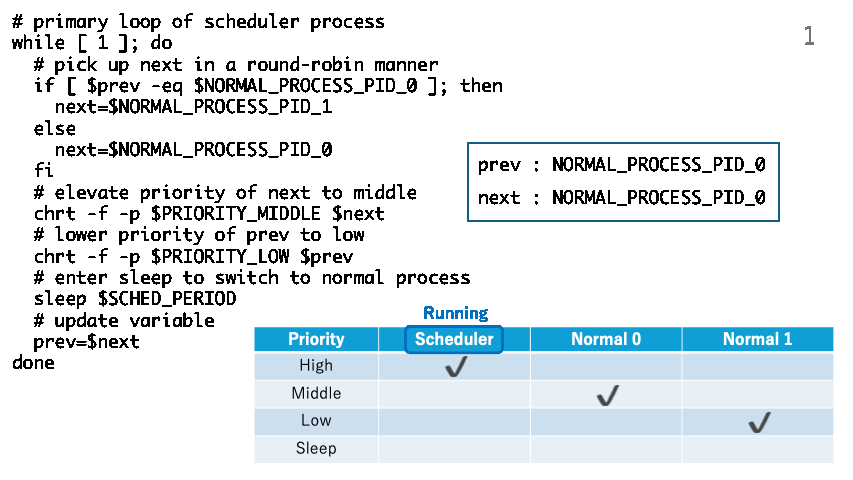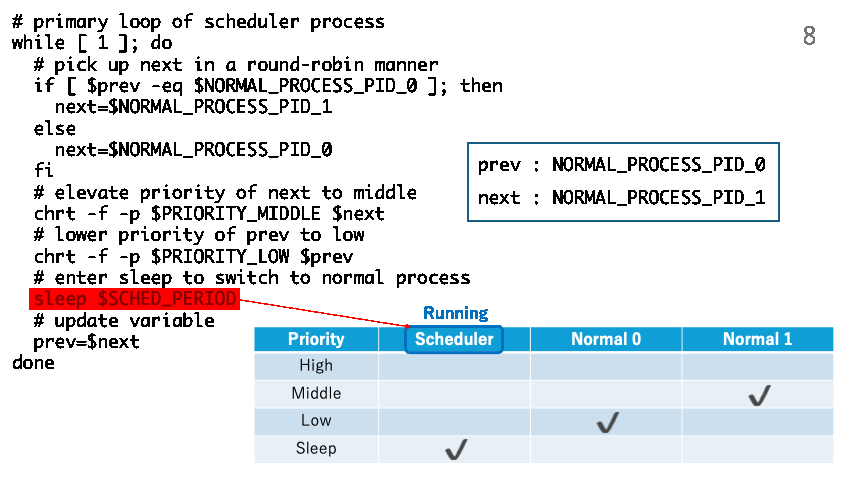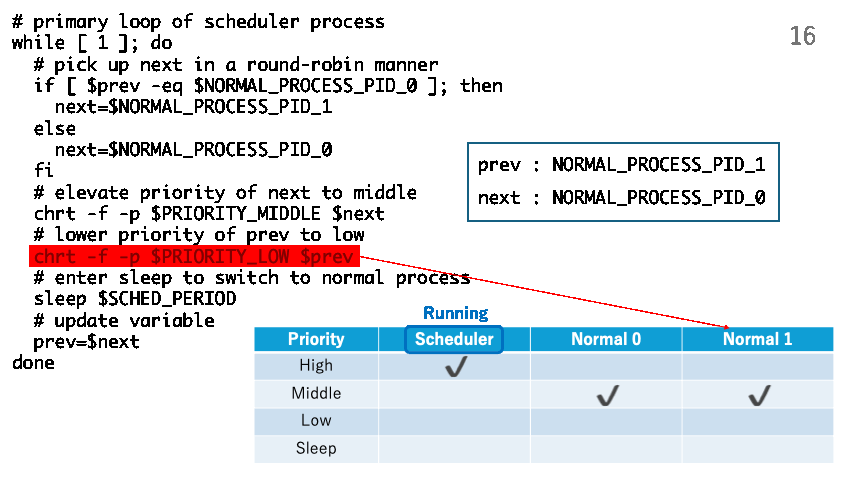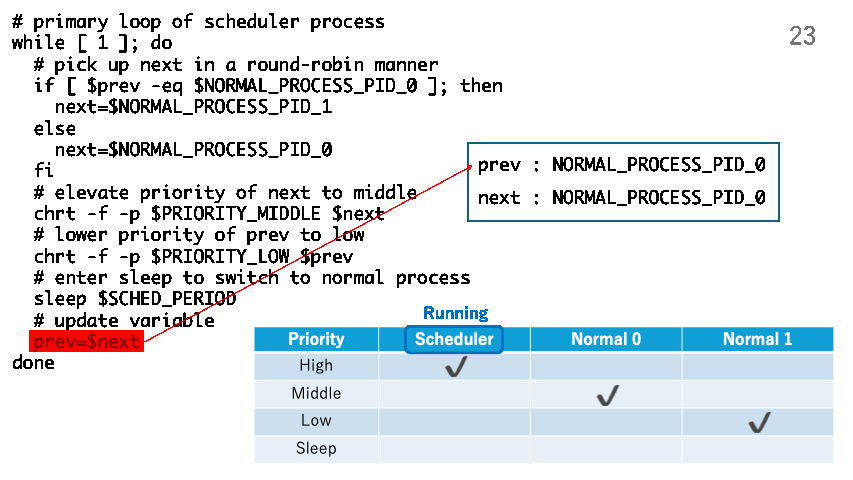
The following is a scheduler process implemented in the C programming language. This also implements a round-robin scheduling policy.
While trick.sh could handle two normal processes, trick.c can schedule up to 8 processes as defined by MAX_PROCESS in the program.
click here to show trick.c
#ifndef _GNU_SOURCE
#define _GNU_SOURCE
#endif
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <unistd.h>
#include <assert.h>
#include <sched.h>
#define MAX_PROCESS (8)
int main(int argc, char *const *argv)
{
pid_t pids[MAX_PROCESS] = { 0 };
int num_process = 0, interval = 0, cpu = -1, s_cpu = -1;
{
struct sched_param sp = { .sched_priority = 3, };
assert(!sched_setscheduler(gettid(), SCHED_FIFO, &sp));
}
{
int ch;
while ((ch = getopt(argc, argv, "c:i:p:s:t:")) != -1) {
switch (ch) {
case 'c':
cpu = atoi(optarg);
break;
case 'i':
interval = atoi(optarg);
break;
case 'p':
assert(num_process < MAX_PROCESS);
pids[num_process++] = atoi(optarg);
break;
case 's':
s_cpu = atoi(optarg);
break;
default:
break;
}
}
}
assert(cpu != -1);
assert(num_process);
assert(interval);
if (s_cpu == -1)
s_cpu = cpu;
{
cpu_set_t c;
CPU_ZERO(&c);
CPU_SET(s_cpu, &c);
assert(!sched_setaffinity(gettid(), sizeof(c), &c));
}
{
int i;
for (i = 0; i < num_process; i++) {
cpu_set_t c;
CPU_ZERO(&c);
CPU_SET(cpu, &c);
assert(!sched_setaffinity(pids[i], sizeof(c), &c));
}
}
while (1) {
int i;
for (i = 0; i < num_process; i++) {
{
struct sched_param sp = { .sched_priority = 2, };
sched_setscheduler(pids[i], SCHED_FIFO, &sp);
}
{
struct sched_param sp = { .sched_priority = 1, };
sched_setscheduler(pids[i == 0 ? num_process -1 : i - 1], SCHED_FIFO, &sp);
}
usleep(interval);
}
}
return 0;
}Once the program is saved as trick.c, you can compile this by the following.
gcc trick.c -o trick
The following command does the same as the example shown for trick.sh.
sudo ./trick -c 1 -p 1522 -p 1523 -i 5000000
The arguments of trick.c are as follows.
-p: pid of a normal process (-pcan be specified several times and up to the limit defined byMAX_PROCESS)-c: CPU core that runs the specified normal processes-s: CPU core that runs the scheduler process (not mandatory, and the scheduler process runs on the CPU core specified by-cif nothing is specified for-s).-i: interval for switching the normal processes (in microseconds)
The following shows how to try the preemptive scheduling mechanism described in the evaluation section.
First, please download the benchmark program and checkout a specific commit.
git clone https://github.com/yasukata/bench-iip.git
cd bench-iip
git checkout 9cf2488ec93ae51f4bd7b18923a5d1a233852f66
Please download the code of a TCP/IP stack and checkout a specific commit.
git clone https://github.com/yasukata/iip.git
cd iip
git checkout d9699776ae98e27eae196157d0f214d6be0014e0
cd ..
Please download the code of a DPDK-based I/O backend and checkout a specific commit.
git clone https://github.com/yasukata/iip-dpdk.git
cd iip-dpdk
git checkout b493a944c13135c38766003606e14d51ca61fc71
cd ..
Please make a directory preemption under bench-iip and put two files main.c and iip_main.c as shown below.
mkdir preemption
cd preemption
Please save the following as main.c in the directory preemption. main.c below implements the preemptive scheduling mechanism using the priority elevation trick, and it also includes the mechanism to mimic bimodal distribution of request processing time (99.5% of requests require 0.5 us, and 0.5% of requests need 500 us).
click here to show main.c
#ifndef _GNU_SOURCE
#define _GNU_SOURCE
#endif
#define __app_loop __o__app_loop
#define __app_thread_init __o__app_thread_init
#pragma push_macro("IOSUB_MAIN_C")
#undef IOSUB_MAIN_C
#define IOSUB_MAIN_C pthread.h
static int __iosub_main(int argc, char *const *argv);
#define IIP_MAIN_C "./iip_main.c"
#include "../main.c"
#undef IOSUB_MAIN_C
#pragma pop_macro("IOSUB_MAIN_C")
#undef iip_ops_tcp_payload
#undef __app_thread_init
#undef __app_loop
#include <stdbool.h>
#include <errno.h>
#include <sched.h>
#include <sys/poll.h>
#include <sys/timerfd.h>
#include <pthread.h>
#define MAX_CORE (128)
#define MAX_DISPATCHER (32)
#define WORKER_PER_CORE (128)
#define SWITCHER_NS (5000)
struct dispatcher {
pthread_t switcher_th;
int timerfd;
uint16_t count;
uint16_t current;
uint16_t pending[WORKER_PER_CORE];
struct {
pthread_t th;
pid_t tid;
uint8_t state;
uint16_t count;
} worker[WORKER_PER_CORE];
struct {
uint16_t head;
uint16_t tail;
struct {
uint16_t count;
void *mem;
void *handle;
void *to;
void *opaque;
} ent[WORKER_PER_CORE];
} req[2];
};
static uint16_t cpu_to_core_id[MAX_CORE] = { 0 };
static struct dispatcher dispatcher[MAX_DISPATCHER] = { 0 };
static volatile bool should_stop = false;
static bool disable_preemptive_scheduling = false;
static inline uint64_t NOW(void)
{
struct timespec ts;
clock_gettime(CLOCK_REALTIME, &ts);
return ts.tv_sec * 1000000000UL + ts.tv_nsec;
}
static void *switcher_fn(void *data)
{
unsigned int core_id;
assert(!getcpu(&core_id, NULL));
core_id = cpu_to_core_id[core_id];
{
struct sched_param sp = { .sched_priority = 4, };
sched_setscheduler(gettid(), SCHED_FIFO, &sp);
}
asm volatile ("" ::: "memory");
printf("switcher started %u\n", gettid());
*((volatile bool *) data) = true;
while (!should_stop) {
again:
{
uint64_t val;
ssize_t err = read(dispatcher[core_id].timerfd, &val, sizeof(val));
if (err == -1) {
if (errno == EINTR) {
printf("read interrupted\n");
goto again;
}
perror("read");
assert(0);
}
}
if (dispatcher[core_id].current != UINT16_MAX) {
//printf("force switch current %u (count %u)\n", dispatcher[core_id].current, dispatcher[core_id].worker[dispatcher[core_id].current].count);
{
struct sched_param sp = { .sched_priority = 1, };
sched_setscheduler(dispatcher[core_id].worker[dispatcher[core_id].current].tid, SCHED_FIFO, &sp);
}
}
}
pthread_exit(NULL);
}
static void *worker_thread_fn(void *data)
{
{
struct sched_param sp = { .sched_priority = 1, };
sched_setscheduler(gettid(), SCHED_FIFO, &sp);
}
uint16_t wid = (uint16_t)((uintptr_t) data);
unsigned int core_id;
assert(!getcpu(&core_id, NULL));
core_id = cpu_to_core_id[core_id];
dispatcher[core_id].worker[wid].tid = gettid();
asm volatile ("" ::: "memory");
while (!should_stop) {
if (dispatcher[core_id].current != wid) {
if (dispatcher[core_id].current != UINT16_MAX)
printf("yield %u %u\n", wid, dispatcher[core_id].current);
sched_yield();
continue;
}
if (dispatcher[core_id].req[0].head == dispatcher[core_id].req[0].tail) { /* nothing to do */
dispatcher[core_id].worker[wid].state = 2;
{ /* go back to dispatcher */
struct sched_param sp = { .sched_priority = 1, };
sched_setscheduler(gettid(), SCHED_FIFO, &sp);
}
} else {
uint16_t t = dispatcher[core_id].req[0].tail;
/* cache values on stack */
void *mem = dispatcher[core_id].req[0].ent[t].mem;
void *handle = dispatcher[core_id].req[0].ent[t].handle;
void *to = dispatcher[core_id].req[0].ent[t].to;
void *opaque = dispatcher[core_id].req[0].ent[t].opaque;
dispatcher[core_id].worker[wid].count = dispatcher[core_id].req[0].ent[t].count;
/* increment tail */
if (++t == WORKER_PER_CORE) t = 0;
asm volatile ("" ::: "memory");
dispatcher[core_id].req[0].tail = t;
if (!disable_preemptive_scheduling) { /* start timer */
struct itimerspec its = {
.it_value.tv_nsec = SWITCHER_NS,
};
timerfd_settime(dispatcher[core_id].timerfd, 0, &its, NULL);
}
{ /* task */
uint64_t start_time = NOW();
while (NOW() - start_time < (dispatcher[core_id].worker[wid].count % 200 == 0 ? 500000 /* long */ : 500 /* short */)) ;
}
if (!disable_preemptive_scheduling) { /* stop timer */
struct itimerspec its = { 0 };
timerfd_settime(dispatcher[core_id].timerfd, 0, &its, NULL);
}
uint16_t h = dispatcher[core_id].req[1].head;
dispatcher[core_id].req[1].ent[h].mem = mem;
dispatcher[core_id].req[1].ent[h].handle = handle;
dispatcher[core_id].req[1].ent[h].to = to;
dispatcher[core_id].req[1].ent[h].opaque = opaque;
if (++h == WORKER_PER_CORE) h = 0;
dispatcher[core_id].req[1].head = h;
}
}
pthread_exit(NULL);
}
static void iip_ops_tcp_payload(void *mem, void *handle, void *m,
void *tcp_opaque, uint16_t head_off, uint16_t tail_off,
void *opaque)
{
unsigned int core_id;
assert(!getcpu(&core_id, NULL));
core_id = cpu_to_core_id[core_id];
{
uint16_t h = dispatcher[core_id].req[0].head;
dispatcher[core_id].req[0].ent[h].count = dispatcher[core_id].count++;
dispatcher[core_id].req[0].ent[h].mem = mem;
dispatcher[core_id].req[0].ent[h].handle = handle;
dispatcher[core_id].req[0].ent[h].to = tcp_opaque;
dispatcher[core_id].req[0].ent[h].opaque = opaque;
if (++h == WORKER_PER_CORE)
h = 0;
asm volatile ("" ::: "memory");
dispatcher[core_id].req[0].head = h;
}
iip_tcp_rxbuf_consumed(mem, handle, 1, opaque);
{ /* unused */
(void) head_off;
(void) tail_off;
(void) m;
}
}
static void __app_loop(void *mem, uint8_t mac[], uint32_t ip4_be, uint32_t *next_us, void *opaque)
{
unsigned int core_id;
assert(!getcpu(&core_id, NULL));
core_id = cpu_to_core_id[core_id];
{
uint16_t i;
for (i = 0; i < WORKER_PER_CORE && dispatcher[core_id].req[0].head != dispatcher[core_id].req[0].tail; i++) {
if (dispatcher[core_id].worker[i].state == 0) {
dispatcher[core_id].current = i;
//printf("dispatch to %u\n", i);
dispatcher[core_id].worker[i].state = 1;
{ /* launch worker thread */
struct sched_param sp = { .sched_priority = 3, };
sched_setscheduler(dispatcher[core_id].worker[i].tid, SCHED_FIFO, &sp);
}
if (dispatcher[core_id].worker[i].state == 2) { /* all task has been done */
//printf("task has been done without pending %u\n", i);
dispatcher[core_id].worker[i].state = 0;
} else {
assert(dispatcher[core_id].worker[i].state == 1);
//printf("worker %u has been preempted\n", i);
}
break;
}
}
}
{ /* run pending tasks */
uint16_t i;
for (i = 0; i < WORKER_PER_CORE; i++) {
if (dispatcher[core_id].worker[i].state == 1) {
dispatcher[core_id].current = i;
{ /* start timer */
struct itimerspec its = {
.it_value.tv_nsec = SWITCHER_NS,
};
timerfd_settime(dispatcher[core_id].timerfd, 0, &its, NULL);
}
//printf("wake up pending %u\n", i);
{ /* launch worker thread */
struct sched_param sp = { .sched_priority = 3, };
sched_setscheduler(dispatcher[core_id].worker[i].tid, SCHED_FIFO, &sp);
}
if (dispatcher[core_id].worker[i].state == 2) { /* all task has been done */
//printf("pending %u has done\n", i);
dispatcher[core_id].worker[i].state = 0;
}
}
}
}
while (dispatcher[core_id].req[1].head != dispatcher[core_id].req[1].tail) {
uint16_t t = dispatcher[core_id].req[1].tail;
__tcp_send_content(dispatcher[core_id].req[1].ent[t].mem,
dispatcher[core_id].req[1].ent[t].handle,
dispatcher[core_id].req[1].ent[t].to,
0, 1,
dispatcher[core_id].req[1].ent[t].opaque);
asm volatile ("" ::: "memory");
if (++t == WORKER_PER_CORE)
t = 0;
dispatcher[core_id].req[1].tail = t;
}
iip_ops_l2_flush(opaque);
dispatcher[core_id].current = UINT16_MAX;
if (__app_should_stop(opaque)) {
should_stop = true;
asm volatile ("" ::: "memory");
{ /* set timer */
struct itimerspec its = { .it_value.tv_nsec = SWITCHER_NS, };
timerfd_settime(dispatcher[core_id].timerfd, 0, &its, NULL);
}
}
__o__app_loop(mem, mac, ip4_be, next_us, opaque);
}
static void *__app_thread_init(void *workspace, uint16_t core_id, void *opaque)
{
if (core_id == 0 && getenv("DISABLE_PREEMPTIVE_SCHEDULING")) {
disable_preemptive_scheduling = true;
printf("preemptive scheduling is disabled\n");
}
{
struct sched_param sp = { .sched_priority = 2, };
sched_setscheduler(gettid(), SCHED_FIFO, &sp);
}
{
unsigned int cpu;
assert(!getcpu(&cpu, NULL));
assert(cpu < MAX_CORE);
cpu_to_core_id[cpu] = core_id;
}
dispatcher[core_id].current = UINT16_MAX;
assert((dispatcher[core_id].timerfd = timerfd_create(CLOCK_REALTIME, 0)) != -1);
{
volatile bool ready = false;
assert(!pthread_create(&dispatcher[core_id].switcher_th, NULL, switcher_fn, (void *) &ready));
while (!ready)
usleep(10000);
}
uint16_t i;
for (i = 0; i < WORKER_PER_CORE; i++) {
dispatcher[core_id].worker[i].tid = -1;
assert(!pthread_create(&dispatcher[core_id].worker[i].th, NULL, worker_thread_fn, (void *)((uintptr_t) i)));
while (dispatcher[core_id].worker[i].tid == -1)
usleep(10000);
}
return __o__app_thread_init(workspace, core_id, opaque);
}
#define M2S(s) _M2S(s)
#define _M2S(s) #s
#include M2S(IOSUB_MAIN_C)
#undef _M2S
#undef M2SPlease save the following as iip_main.c in the directory preemption.
click here to show iip_main.c
#include "../iip/main.c"
#define iip_ops_tcp_payload __o_iip_ops_tcp_payload
Then, please type the following to build the application.
IOSUB_DIR=../iip-dpdk make -f ../Makefile
This program uses DPDK that requires huge pages. If your system does not have huge pages, the following command configures 2GB of huge pages.
sudo ../iip-dpdk/dpdk/dpdk-23.07/usertools/dpdk-hugepages.py -p 2M -r 2G
Then, the following command launches the compiled program, namely, a networked server that works with the preemptive scheduling policy.
sudo LD_LIBRARY_PATH=../iip-dpdk/dpdk/install/lib/x86_64-linux-gnu ./a.out -n 1 -l 31 --proc-type=primary --file-prefix=pmd1 --allow 17:00.0 -- -a 0,10.100.0.20 -- -p 10000 -m "```echo -e 'HTTP/1.1 200 OK\r\nContent-Length: 2\r\nConnection: keep-alive\r\n\r\nAA'```"
To run a test, we can use the wrk2 benchmark. We assume the following command is executed on another machine that is reachable to the machine running the networked server launched by the command above.
./wrk http://10.100.0.20:10000/ -d 5 -t 32 -c 32 -R 20000 --u_latency
wrk2 provides the latency distribution through the output like the following.
50.000% 34.00us
75.000% 37.00us
90.000% 56.00us
99.000% 107.00us
99.900% 539.00us
99.990% 562.00us
99.999% 579.00us
100.000% 607.00us
We can compare this with a version that does not activate the preemptive scheduling mechanism by the following command that specifies an environment variable DISABLE_PREEMPTIVE_SCHEDULING.
sudo DISABLE_PREEMPTIVE_SCHEDULING=1 LD_LIBRARY_PATH=../iip-dpdk/dpdk/install/lib/x86_64-linux-gnu ./a.out -n 1 -l 31 --proc-type=primary --file-prefix=pmd1 --allow 17:00.0 -- -a 0,10.100.0.20 -- -p 10000 -m "```echo -e 'HTTP/1.1 200 OK\r\nContent-Length: 2\r\nConnection: keep-alive\r\n\r\nAA'```"
We run the same wrk2 command, and the following is the latency output from wrk2.
50.000% 34.00us
75.000% 37.00us
90.000% 54.00us
99.000% 539.00us
99.900% 580.00us
99.990% 620.00us
99.999% 650.00us
100.000% 659.00us
We find the 99th percentile latency difference between these two cases: 107 us and 539 us.
This gap comes from the preepmtive scheduling that mitigates the head-of-line blocking issue.