The project inherits from the Langchain-Chatchat project(https://github.com/chatchat-space/Langchain-Chatchat) The underlying architecture uses open-source frameworks such as Langchain and Fastchat, with the top layer implemented in Streamlit. The project is completely open-source, aiming for offline deployment and testing of most open-source models from the Hugging Face website. Additionally, it allows combining multiple models through configuration to achieve multimodal, RAG, Agent, and other functionalities.

- Quick Start
- Video Demonstration
- Project Introduction
- Environment Setup
- Feature Overview
Please first prepare the runtime environment, refer to Environment Setup
If deploying locally, you can start the Web UI using Python with an HTTP interface at http://127.0.0.1:8818
python __webgui_server__.py --webuiIf deploying on a cloud server and accessing the Web UI locally, Please use reverse proxy and start the Web UI with HTTPS. Access using https://127.0.0.1:4480 on locally, and use the https interface at https://[server ip]:4480 on remotely:
// By default, the batch file uses the virtual environment named keras-llm-robot,
// Modify the batch file if using a different virtual environment name.
// windows platform
webui-startup-windows.bat
// ubuntu(linux) platform
python __webgui_server__.py --webui
chmod +x ./tools/ssl-proxy-linux
./tools/ssl-proxy-linux -from 0.0.0.0:4480 -to 127.0.0.1:8818
// MacOS platform
python __webgui_server__.py --webui
chmod +x ./tools/ssl-proxy-darwin
./tools/ssl-proxy-darwin -from 0.0.0.0:4480 -to 127.0.0.1:8818As an example with Ubuntu, You can access the Server from other PCs on the local network after starting the reverse proxy with ssl-proxy-darwin:

Start Server on Ubuntu.

Start Reverse Proxy on Ubuntu.

Access Server on Windows PC by https service.
It is recommended to use the .env method to load the keys for online services. Please rename ./WebUI/configs/.env.sample to .env and fill in the required key information according to your needs:
OPENAI_API_KEY=
GOOGLE_API_KEY=
GROQ_API_KEY=
ALI_API_KEY=
YI_API_KEY=
KIMI_API_KEY=
QIANFAN_ACCESS_KEY=
QIANFAN_SECRET_KEY=
TOGETHER_API_KEY=
FIREWORKS_API_KEY=
SPEECH_KEY=
SPEECH_REGION=
BING_SEARCH_URL=https://api.bing.microsoft.com/v7.0/search
BING_SUBSCRIPTION_KEY=
METAPHOR_API_KEY=
GOOGLE_CSE_ID=
GOOGLE_SEARCH_KEY=
GOOGLE_JSON_CREDENTIALS=
Consists of three main interfaces: the chat interface for language models, the configuration interface for language models, and the tools and agent interface for auxiliary models.
Chat Interface:
 The language model is the foundation model that can be used in chat mode after loading. It also serves as the brain in multimodal features. Auxiliary models, such as voice, image, and retrieval models, require language models to process their input or output text. The voice model like to ear and mouth, the image model like to eye, and the retrieval model provides long-term memory. The project currently supports dozens of language models.
The language model is the foundation model that can be used in chat mode after loading. It also serves as the brain in multimodal features. Auxiliary models, such as voice, image, and retrieval models, require language models to process their input or output text. The voice model like to ear and mouth, the image model like to eye, and the retrieval model provides long-term memory. The project currently supports dozens of language models.
Configuration Interface:
 Models can be loaded based on requirements, categorized into general, multimodal, special, and online models.
Models can be loaded based on requirements, categorized into general, multimodal, special, and online models.
Tools & Agent Interface:
 Auxiliary models, such as retrieval, code execution, text-to-speech, speech-to-text, image recognition, and image generation, it can be loaded based on requirements. The tools section includes settings for function calls (requires language model support for function calling).
Auxiliary models, such as retrieval, code execution, text-to-speech, speech-to-text, image recognition, and image generation, it can be loaded based on requirements. The tools section includes settings for function calls (requires language model support for function calling).
- Install Anaconda or Miniconda and Git. Windows users also need to install the CMake tool, Ubuntu users need to install gcc tools.
// In a clean environment on Ubuntu, follow the steps below to pre-install the packages:
// install gcc
sudo apt update
sudo apt install build-essential
// install for ffmpeg
sudo apt install ffmpeg
// install for pyaudio
sudo apt-get install portaudio19-dev
// The default installation of requestment is for the faiss-cpu. If you need to install the faiss-gpu
pip3 install faiss-gpu- Create a virtual environment named keras-llm-robot using conda and install Python of 3.10 or 3.11:
conda create -n keras-llm-robot python==3.11.5- Clone the repository:
git clone https://github.com/smalltong02/keras-llm-robot.git
cd keras-llm-robot- Activate the virtual environment:
conda activate keras-llm-robot- If you have an NVIDIA GPU, Please install the CUDA Toolkit from (https://developer.nvidia.com/cuda-toolkit-archive), and install the PyTorch CUDA version in the virtual environment (same to the CUDA Toolkit version https://pytorch.org/):
// such as install version 12.1
conda install pytorch=2.1.2 torchvision=0.16.2 torchaudio=2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia- Install dependencies, Please choose the appropriate requirements file based on your platform, On the Windows, if encounter compilation errors for llama-cpp-python or tts during the installation, please remove these two packages from the requirements:
// windows
pip install -r requirements-windows.txt
// Ubuntu
pip install -r requirements-ubuntu.txt
// MacOS
pip install -r requirements-macos.txt- If speech feature is required, you also need to install the ffmpeg tool.
// For Windows:
Download the Windows binary package of ffmpeg from (https://www.gyan.dev/ffmpeg/builds/).
Add the bin directory to the system PATH environment variable.
// for ubuntu, install ffmpeg and pyaudio
sudo apt install ffmpeg
sudo apt-get install portaudio19-dev
// For MacOS
```bash
# Using libav
brew install libav
#### OR #####
# Using ffmpeg
brew install ffmpeg
```
- If you need to download models from Hugging Face for offline execution, please download the models yourself and place them in the "models" directory. If the models have not been downloaded in advance, the WebUI will automatically download them from the Hugging Face website to the local system cache.
// such as the folder of llama-2-7b-chat model:
models\llm\Llama-2-7b-chat-hf
// such as the folder of XTTS-v2 speech-to-text model:
models\voices\XTTS-v2
// such as the folder of faster-whisper-large-v3 text-to-speech model:
models\voices\faster-whisper-large-v3-
When using the
OpenDalleV1.1model to generate images, if using 16-bit precision, please download thesdxl-vae-fp16-fixmodel from Huggingface and place it in themodels\imagegenerationfolder. If enabling the Refiner, please download thestable-diffusion-xl-refiner-1.0model from Huggingface and place it in themodels\imagegenerationfolder beforehand. -
When using the Model
stable-video-diffusion-img2vidandstable-video-diffusion-img2vid-xt, it is necessary to install ffmpeg and the corresponding dependencies first:1. download generative-models from https://github.com/Stability-AI/generative-models in project root folder. 2. cd generative-models & pip install . 3. pip install pytorch-lightning pip install kornia pip install open_clip_torch
11. Some model loading, as well as fine-tuning and quantization features require the `flash-attn` and `bitsandbytes` libraries, please install them using the following method.
```bash
# For Linux,Takes about 1 hour to compile and install。
pip install flash-attn
pip install bitsandbytes
# The Download URL of Windows, Please take care to select the correct CUDA Tookit version, Torch version and Python version.
https://github.com/bdashore3/flash-attention/releases
https://github.com/jllllll/bitsandbytes-windows-webui/releases
# After downloading, please use the following command to install
pip install *.whl
# MacOS version is not supported
```
- If run locally, start the Web UI using Python at http://127.0.0.1:8818:
```bash
python __webgui_server__.py --webui
```
- If deploying on a cloud server and accessing the Web UI locally, use reverse proxy and start the Web UI with HTTPS. Access using https://127.0.0.1:4480 on locally, and use the https interface at https://[server ip]:4480 on remotely:
```bash
// By default, the batch file uses the virtual environment named keras-llm-robot,
// Modify the batch file if using a different virtual environment name.
webui-startup-windows.bat
// ubuntu(linux)
python __webgui_server__.py --webui
chmod +x ./tools/ssl-proxy-linux
./tools/ssl-proxy-linux -from 0.0.0.0:4480 -to 127.0.0.1:8818
// MacOS
python __webgui_server__.py --webui
chmod +x ./tools/ssl-proxy-darwin
./tools/ssl-proxy-darwin -from 0.0.0.0:4480 -to 127.0.0.1:8818
```
-
In the configuration interface, you can choose suitable language models to load, categorized as
Foundation Models,Multimodal Models,Special Models, andOnline Models.Foundation ModelsUntouched models published on Hugging Face, supporting models with chat templates similar to OpenAI.Multimodal ModelsModels supporting both voice and text or image and text at the lower level.Code ModelsCode generation model.Special ModelsQuantized models (GGUF) published on Hugging Face or models requiring special chat templates.Online ModelsSupports online language models from OpenAI and Google, such as GPT4-Turbo, Gemini-Pro, GPT4-vision, and Gemini-Pro-vision. Requires OpenAI API Key and Google API Key, which can be configured in the system environment variables or in the configuration interface.
-
In the tools & agent interface, you can load auxiliary models such as retrieval, code execution, text-to-speech, speech-to-text, image recognition, image generation, or function calling.
RetrievalSupports both local and online vector databases, local and online embedding models, and various document types. Can provide long-term memory for the Foundation model.Code InterpreterSupports local interpreter "keras-llm-interpreter".Text-to-SpeechSupports local model XTTS-v2 and Azure online text-to-speech service. Requires Azure API Key, which can be configured in the system environment variablesSPEECH_KEYandSPEECH_REGION, or in the configuration interface.Speech-to-TextSupports local models whisper and fast-whisper and Azure online speech-to-text service. Requires Azure API Key, which can be configured in the system environment variablesSPEECH_KEYandSPEECH_REGION, or in the configuration interface.Image RecognitionSupports local model blip-image-captioning-large.Image GenerationSupports local model OpenDalleV1.1 for static image generation and local model stable-video-diffusion-img2vid-xt for dynamic image generation.Function CallingYou can configure function calling to empower models with the ability to use utilities.
Once the speech-to-text model is loaded, voice and video chat controls will appear in the chat interface. Click the START button to record voice via the microphone and the STOP button to end the voice recording. The speech model will automatically convert the speech to text and engage in conversation with the language model. When the text-to-speech model is loaded, the text output by the language model will automatically be converted to speech and output through speakers and headphones.

Once the Multimodal model is loaded(such as Gemini-Pro-Vision),upload controls will appear in the chat interface, The restrictions on uploading files depend on the loaded model. After sending text in the chatbox, both uploaded files and text will be forwarded to the multimodal model for processing.

-
-
Load ModelFoundation Models can be loaded with CPU or GPU, and with 8-bits loading (
4-bits is invalid). Set the appropriate CPU Threads to improve token output speed when using CPU. When encountering the error 'Using Exllama backend requires all the modules to be on GPU' while loading the GPTQ model, please add "'disable_exllama': true" in the 'quantization_config' section of the model's config.json.Multimodal models can be loaded with CPU or GPU. For Vision models, users can upload images and text for model interaction. For Voice models, users can interact with the model using a microphone (without the need for auxiliary models). (
Not implemented)Special models can be loaded with CPU or GPU, Please prioritize CPU loading of GGUF models.
Online models do not require additional local resources and currently support online language models from OpenAI and Google.
NOTEWhen the TTS library is not installed, XTTS-2 local speech models cannot be loaded, but other online speech services can still be used. If the llama-cpp-python library is not installed, the GGUF model cannot be loaded. Without a GPU device, AWQ and GPTQ models cannot be loaded.Supported Models Model Type Size fastchat-t5-3b-v1.0 LLM Model 3B llama-2-7b-hf LLM Model 7B llama-2-7b-chat-hf LLM Model 7B chatglm2-6b LLM Model 7B chatglm2-6b-32k LLM Model 7B chatglm3-6b LLM Model 7B tigerbot-7b-chat LLM Model 7B openchat_3.5 LLM Model 7B Qwen-7B-Chat-Int4 LLM Model 7B fuyu-8b LLM Model 7B Yi-6B-Chat-4bits LLM Model 7B neural-chat-7b-v3-1 LLM Model 7B Mistral-7B-Instruct-v0.2 LLM Model 7B llama-2-13b-hf LLM Model 13B llama-2-13b-chat-hf LLM Model 13B tigerbot-13b-chat LLM Model 13B Qwen-14B-Chat LLM Model 13B Qwen-14B-Chat-Int4 LLM Model 13B Yi-34B-Chat-4bits LLM Model 34B llama-2-70b-hf LLM Model 70B llama-2-70b-chat-hf LLM Model 70B cogvlm-chat-hf Multimodal Model (image) 7B Qwen-VL-Chat Multimodal Model (image) 7B Qwen-VL-Chat-Int4 Multimodal Model (image) 7B stable-video-diffusion-img2vid Multimodal Model (image) 7B stable-video-diffusion-img2vid-xt Multimodal Model (image) 7B Qwen-Audio-Chat Multimodal Model (image) 7B phi-2-gguf Special Model 3B phi-2 Special Model 3B Yi-6B-Chat-gguf Special Model 7B OpenHermes-2.5-Mistral-7B Special Model 7B Yi-34B-Chat-gguf Special Model 34B Mixtral-8x7B-v0.1-gguf Special Model 8*7B gpt-3.5-turbo Online Model *B gpt-3.5-turbo-16k Online Model *B gpt-4 Online Model *B gpt-4-32k Online Model *B gpt-4-1106-preview Online Model *B gpt-4-vision-preview Online Model *B gemini-pro Online Model *B gemini-pro-vision Online Model *B chat-bison-001 Online Model *B text-bison-001 Online Model *B whisper-base Voice Model *B whisper-medium Voice Model *B whisper-large-v3 Voice Model *B faster-whisper-large-v3 Voice Model *B AzureVoiceService Voice Model *B XTTS-v2 Speech Model *B AzureSpeechService Speech Model *B OpenAISpeechService Speech Model *B Notes for Multimodal Models-
The Model
cogvlm-chat-hf,Qwen-VL-Chat, andQwen-VL-Chat-Int4support single-image file input with text input, capable of recognizing image content and answering questions about the image based on natural language. -
The Model
stable-video-diffusion-img2vidandstable-video-diffusion-img2vid-xtsupport single-image file input and generate video based on the image.When using these two models, it is necessary to install ffmpeg and the corresponding dependencies first:
1. download generative-models from https://github.com/Stability-AI/generative-models in project root folder. 2. cd generative-models & pip install . 3. pip install pytorch-lightning pip install kornia pip install open_clip_torch
-
The Model
Qwen-Audio-Chatsupports single audio file input with text input and provides responses to the content of the audio file based on natural language.
-
-
QuantizationUse open-source tools like llama.cpp to create quantized versions of general models with 2, 3, 4, 5, 6, and 8 bits.
Not implemented -
Fine-tuningYou can fine-tune the language model using a private dataset. The current integration includes the open-source project
unslothand allows model fine-tuning on Linux systems.# Preparations for fine-tuning: after installing requirements-ubuntu.txt, follow these steps to install the necessary packages for model fine-tuning. 1. pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git" 2. pip install --no-deps trl peft accelerate bitsandbytes
Currently,
unslothsupports the following models: Qwen 1.5 (7B, 14B, 32B, 72B), Llama3-8B, Mistral (v0.3)-7B, Gemma, CodeGemma, ORPO, DPO Zephyr, Phi-3 mini & medium, TinyLlama -
Role PlayYou can have offline or online LLM Models play different roles to provide more professional responses.
Support english and chinese roles.
Currently supported roles include:
Role English Translator Interviewer Spoken English Teacher Travel Guide Advertiser Storyteller Stand-up Comedian Debater Screenwriter Novelist Movie Critic Poet Rapper Motivational Speaker Math Teacher Career Counselor Doctor Dentist Chef Automobile Mechanic Text Based Adventure Game Fancy Title Generator Yogi Essay Writer Food Critic Machine Learning Engineer Regex Generator Startup Idea Generator Product Manager
-
-
-
RetrievalRAG functionality requires a vector database and embedding models to provide long-term memory capabilities to the language model.
Support the following Vector Database:
Databases Type Faiss Local Milvus Local PGVector Local ElasticsearchStore Local ZILLIZ Online Support the following Embedding Models:
Model Type Size bge-small-en-v1.5 Local 130MB bge-base-en-v1.5 Local 430MB bge-large-en-v1.5 Local 1.3GB bge-small-zh-v1.5 Local 93MB bge-base-zh-v1.5 Local 400MB bge-large-zh-v1.5 Local 1.3GB m3e-small Local 93MB m3e-base Local 400MB m3e-large Local 1.3GB text2vec-base-chinese Local 400MB text2vec-bge-large-chinese Local 1.3GB text-embedding-ada-002 Online *B embedding-gecko-001 Online *B embedding-001 Online *B NOTEPlease download the embedding model in advance and place it in the specified folder, otherwise the document vectorization will not be possible, and uploading to the knowledge base will also fail.NOTEWhen using the Milvus database, it is recommended to deploy it locally or on a Kubernetes (k8s) cluster using Docker. Please refer to the official Milvus documentation and download the docker file at https://github.com/milvus-io/milvus/releases/download/v2.3.0/milvus-standalone-docker-compose.yml .1. please rename it to docker-compose.yml When download was finished. 2. Create local folder for Milvus and copy the file docker-compose.yml into it. 3. create sub folder conf, db, logs, pic, volumes, wal 4. Execute the command in that folder docker-compose up -d 5. Please check whether the image deployment is successful in the Docker interface. and ensure that the image is running and listening on ports 19530 and 9091.
NOTEWhen using the PGVector database,it is recommended to deploy it locally using Docker.1. Execute the command for download image. docker pull ankane/pgvector 2. Deploy the container using the following command, and modify the DB name, username, and password as needed. (Please also update the 'connection_uri' configuration in kbconfig.json under 'pg'). docker run --name pgvector -e POSTGRES_DB=keras-llm-robot -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=postgres -p 5432:5432 -d ankane/pgvector 3. Please check whether the image deployment is successful in the Docker interface. and ensure that the image is running and listening on ports 5432.
As an example with Ubuntu, after successfully launching the server-side of Milvus and PGVector, you can check them in Docker Desktop. Additionally, you can install clients such as attu or pgAdmin to manage vector DB:

Support the following Documents:
html, mhtml, md, json, jsonl, csv, pdf, png, jpg, jpeg, bmp, eml, msg, epub, xlsx, xls, xlsd, ipynb, odt, py, rst, rtf, srt, toml, tsv, docx, doc, xml, ppt, pptx, enex, txt
Knowledge Base Interface:
 When creating a new knowledge base, please enter the name and introduction of the knowledge base, and select an appropriate vector database and embedding model. If the document content of the knowledge base is in English, it is recommended to choose the local model
When creating a new knowledge base, please enter the name and introduction of the knowledge base, and select an appropriate vector database and embedding model. If the document content of the knowledge base is in English, it is recommended to choose the local model bge-large-en-v1.5; if the content is predominantly in Chinese with some English, it is recommended to choosebge-large-zh-v1.5orm3e-large.Upload Documents Interface:
 You can choose to upload one or multiple documents at a time. During the document upload, content extraction, split, vectorization, and addition to the vector database will be performed. The process may take a considerable amount of time, so please be patient.
You can choose to upload one or multiple documents at a time. During the document upload, content extraction, split, vectorization, and addition to the vector database will be performed. The process may take a considerable amount of time, so please be patient.Documents Content Interface:
 You can inspect the content of document slices and export them.
You can inspect the content of document slices and export them.Knowledge Base Chat Interface:
 In the chat interface, you can select a knowledge base, and the Foundation model will answer user queries based on the content within the selected knowledge base.
In the chat interface, you can select a knowledge base, and the Foundation model will answer user queries based on the content within the selected knowledge base. -
Code InterpreterEnable code execution capability for the language model to empower it with actionable functionality for the mind.
Keras-llm-interpreter provides two modes for usage: the first is the local execution mode, which runs code on the local PC, allowing modifications to the local PC environment; the second is the Docker image mode, providing a more secure execution environment as it operates within a sandbox, ensuring that running code does not affect the local PC environment.
(1) Local Execution Mode
First, configure the local execution environment:
pip install ipykernel pip install ipython python -m ipykernel install --name "python3" --user(2) Docker Image Mode
Downloading the Docker image:
1. Execute the command to download the image: docker pull smalltong02/keras-interpreter-terminal 2. Deploy the container using the following command, adjusting the port as needed: docker run -d -p 20020:20020 smalltong02/keras-interpreter-terminal 3. Check in the Docker interface to ensure that the image deployment was successful, ensure that the image is running, and listening on port 20020.
(3) Enable the code interpreter and run a task demonstration:
Enable the code interpreter feature:

Load model Meta-Llama-3-8B-Instruct,Plot Tesla and Apple stock price YTD from 2024:


Use Python language to draw an image of a pink pig and display it:



create a word cloud image based on the file "wordcloud.txt" and display it:


-
Speech Recognition and GenerationProvide the language model with speech input and output capabilities, adding the functions of listening and speaking to the mind. Support local models such as XTTS-v2 and Whisper, as well as integration with Azure online speech services.
-
Image Recognition and GenerationProvide the language model with input and output capabilities for images and videos, adding the functions of sight and drawing to the mind.
Support the following Image:
png, jpg, jpeg, bmp
Model Type Size blip-image-captioning-large Image Recognition Model *B OpenDalleV1.1 Image Generation Model *B When using the
OpenDalleV1.1model to generate images, if using 16-bit precision, please download thesdxl-vae-fp16-fixmodel from Huggingface and place it in themodels\imagegenerationfolder. If enabling the Refiner, please download thestable-diffusion-xl-refiner-1.0model from Huggingface and place it in themodels\imagegenerationfolder beforehand.Image Recognition:

Static image generation:




Dynamic image generation:

-
Network Search EngineProviding language models with network retrieval capabilities adds the ability for the brain to retrieve the latest knowledge from the internet.
Support the following Network Search Engine:
Network Search Engine Key duckduckgo No bing Yes metaphor Yes When use
bingandmetaphorsearch engine,Please apply and config API Key first.Please install the following packages before using the network search engine.
1. pip install duckduckgo-search 2. pip install exa-py 3. pip install markdownify 4. pip install strsimpy
Support smart feature, The smart feature allows the model to autonomously decide whether to use a search engine when answering questions -
Function CallingProvide the language model with function calling capability, empowering the mind with the ability to use tools.
Add two function,get_current_time() return current time;get_current_location() return current location.
Enable Function Calling Feature:

Disable Function Calling feature:

-
ToolBoxes
Providing a Toolbox Functionality for Language Models: Enhance the Model with More Tools
Supported Google ToolBoxes, Tools included: "Google Mail", "Google Calendar", "Google Drive", "Google Maps", "YouTube"
By integrating these tools, the model can efficiently perform tasks such as sending emails, managing reminders, handling cloud storage, navigating maps, and searching for YouTube videos.
To use the Google ToolBox feature, you need to sign up for an account on Google Cloud Platform, generate OAuth 2.0 credentials, download the token in JSON format, and then import it through the WebUI. -
-
We combine various models and tools to create efficient and productive AI agents.
Intelligent Customer Service Agent
The design goal of the intelligent customer service agent is to provide users with efficient, personalized, and accurate customer service, thereby improving customer experience and satisfaction. To achieve this goal, intelligent customer service agents typically should possess the following capabilities:
(1) Natural Language Processing (NLP) Capability: Intelligent customer service agents need to understand user input in natural language, including text, speech, or images. NLP techniques can assist the agent in understanding user intents, questions, or needs.
(2) Knowledge Base Management Capability: The agent should be able to manage and update a knowledge base, including FAQs, solutions, product information, etc. Continuous updating and optimization of the knowledge base can enhance the agent's accuracy and speed in problem-solving.
(3) Automatic Response and Routing: The agent should automatically identify user queries and provide relevant responses or route them to appropriate human agents or departments. This helps in reducing user wait times and improving service efficiency.
(4) Personalized Recommendations and Suggestions: Based on user history and behavior, the agent should offer personalized recommendations and suggestions to help users find solutions or products more quickly.
(5) Multi-Channel Support: The agent should provide service across various communication channels, including website chat, mobile apps, social media, etc. This ensures meeting user needs across different platforms and maintaining a consistent service experience.
(6) User Authentication and Data Security: The agent should authenticate users and ensure the security and privacy of user data, thereby building user trust and complying with relevant laws and regulations.
Real-time Language Translation Agent
The design goal of the AI real-time language translation agent is to achieve real-time translation between different languages, enabling users to smoothly engage in cross-language communication and interaction. To achieve this goal, AI real-time language translation agents typically should possess the following capabilities:
(1) Multi-Language Support: The agent should support translation across multiple languages, including common global languages and regional dialects, to cater to diverse user needs.
(2) Real-time Translation: The agent should translate user input text or speech into the target language in real-time, displaying or playing back the translation promptly to ensure timely and fluent communication.
(3) High Accuracy: The agent should maintain high translation accuracy, accurately conveying the meaning of the original language and avoiding ambiguity and misunderstandings as much as possible.
(4) Contextual Understanding: The agent needs to understand the context of the text or speech and translate accordingly to ensure that the translation aligns with the context and effectively communicates the message.
(5) Speech Recognition and Synthesis: For speech input and output, the agent needs to have speech recognition and synthesis capabilities to enable speech translation functionality.
(6) Personalization Settings: The agent should allow users to personalize settings according to their preferences and needs, such as selecting preferred languages, adjusting translation speeds, etc.
(7) Data Security and Privacy Protection: The agent should ensure the security and privacy of user-input text or speech data, adhering to relevant data protection laws and standards.
Virtual Personal Assistant Agent
Combining natural language processing with image and speech recognition to create a virtual personal assistant capable of understanding and executing user commands.
(1) Enhancing Productivity and Efficiency:
Automating routine tasks such as scheduling, setting reminders, and sending emails, allowing users to focus on more important work. Providing intelligent recommendations and personalized suggestions to help users complete tasks more efficiently.(2) Improving User Experience:
Offering 24/7 service, eliminating the need to wait for human customer support. Providing natural language interaction, making communication with the assistant smoother and more intuitive. Customizing services based on the user's habits and preferences.(3) Information Management and Retrieval:
Quickly obtaining and organizing information to answer user questions and provide real-time advice and decision support. Automating data processing and analysis, such as handling documents and generating reports.(4) Supporting Decision-Making and Planning:
Helping users make more informed decisions by providing relevant information and analysis. Supporting complex planning and scheduling, such as travel arrangements and project management.(5) Enhancing Communication and Collaboration:
Assisting with team communication management, arranging meetings, and recording meeting minutes. Providing translation and language support to help users work in different language environments.(6) Improving Quality of Life:
Offering health management, fitness advice, and psychological counseling services to help users maintain a healthy lifestyle. Providing entertainment and learning resource recommendations to enrich users' leisure time.(7) Supporting Innovation and Creativity:
Helping users brainstorm and providing creative ideas and inspiration. Assisting with creative tasks such as writing and designing.




















- Agent for Virtual Personal Assistant:

- Real-time Language Translation Agent:

- The demonstration YI-1.5-9B-Chat + Intelligent Customer Agent:

- Gemini-1.5-pro + Intelligent Customer Agent:

- The demonstration Llama-3-8B + Keras Code Interpreter:

- The demonstration Phi-3-mini + Keras Code Interpreter:

- The demonstration Llama-3-8B + Function Calling:

- The demonstration Phi-3-mini + Function Calling:

- The demonstration utilizes a multimodal online model GPT-4-vision-preview along with Azure Speech to Text services:
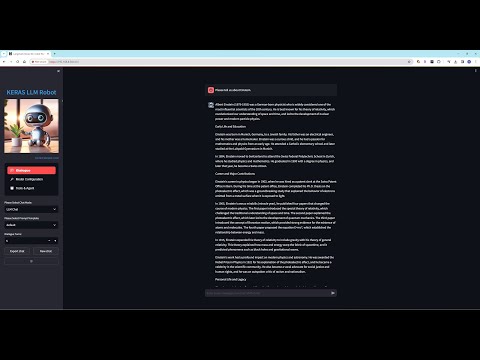
- The demonstration gpt-4-vision-preview VS Gemini-pro-vision:

- The demonstration of the Retrieval Augmented Generation (RAG) feature:

- Demonstration of Image Recognition and Image Generation Features:
Presentation of text to image, translating natural language into the CLIP for image generation models:
 |
| 
 |
| 
Creating Handicrafts Based on Items in the Picture:

- 🚀 Update Log for 2024-06-30
- Support for
gemma-2-9b-it,gemma-2-27b-it, Please upgradetransformersto4.42.3. (pip install transformers==4.42.3) - Support for
Qwen2-0.5B-Instruct,Qwen2-1.5B-Instruct,Qwen2-7B-Instruct
- 🚀 Update Log for 2024-06-27
- add
.envconfiguration file
- 🚀 Update Log for 2024-06-18
- support
google photostool. - support
together aiandfirework ai.
-
🚀 Update Log for 2024-06-15
-
Refactor the code to support the modes
"LLM Chat","Knowledge Base Chat","File Chat"and"Agent Chat"on the main interface.In
"LLM Chat"the model will use all activated tools to assist in the conversation.In
"Knowledge Base Chat"the model will only use the selected knowledge base for the conversation, with all other activated tools being disabled.In
"File Chat"the model will only use the selected file for the conversation, with all other activated tools being disabled.In
"Agent Chat"the model will only use the selected code interpreter to complete tasks, with all other activated tools being disabled. -
Support the
native Function Callfeature for theGemini model,GPT model, andKimi model. -
Add the
Keras code interpreterto the toolbox. When the code interpreter is activated, the model in "LLM Chat" will autonomously decide whether to invoke this tool.
-
-
🚀 Update Log for 2024-06-05
- Support for
glm-4v-9b,glm-4-9b-chat,glm-4-9b-chat-1m
- Support for
-
🚀 Update Log for 2024-06-03
- Support for
MiniCPM-Llama3-V-2_5
- Support for
-
🚀 Update Log for 2024-06-02
- Support for
Phi-3-vision-128k-instruct, please install theflash-attnlibrary first.
# for Linux, Takes about 1 hour to compile and install. pip install flash-attn # Download URL of Windows,Please take care to select the correct CUDA Tookit version, Torch version and Python version. https://github.com/bdashore3/flash-attention/releases # After downloading, please use the following command to install pip install *.whl
- Support for
-
🚀 Update Log for 2024-05-28
- Support Google ToolBoxes: "Google Mail", "Google Calendar", "Google Drive", "Google Maps", "Youtube"
- Introduced features "Virtual Personal Assistant".
-
🚀 Update Log for 2024-05-20
- Added support for the online model platform Groq.
- Introduced features "Intelligent Customer Agent" and "Real-time Translation Agent."
-
🚀 Update Log for 2024-05-15
- Support for google search
- fix issue for duckduckgo
-
🚀 Update Log for 2024-05-14
- Support for YI cloud platform models.
- Support for Qwen1.5-32B-Chat-GPTQ-Int4 and Yi-1.5-34B-Chat-GPTQ-Int4
-
🚀 Update Log for 2024-05-13
- Support for gpt-4o of OpenAI
- Support for Yi-1.5-6B-Chat and Yi-1.5-9B-Chat
- Support for "Intelligent Customer Support"
-
🚀 Update Log for 2024-05-01
- Fix issue for GGUF model.
- Support for Llama3-8B-Chinese-Chat.
-
🚀 Update Log for 2024-04-28
- Support for Function Calling feature.
- Updated Keras LLM Interpreter.
-
🚀 Update Log for 2024-04-19
- Support for models Meta-Llama-3-8B and Meta-Llama-3-8B-Instruct.
- Introduced a new feature called "Role-Playing," enabling offline or online models to take on different roles. For example, you can have the LLM Model role-play as an "English Translator," "Interviewer," "Novelist," "Product Manager," "Yogi" and more, thereby providing more specialized responses.
-
🚀 Update Log for 2024-04-15
- Support for models Orion-14B-Chat, Orion-14B-LongChat and Orion-14B-Chat-Int4. To correctly load the model and perform inference, please install the
flash-attnlibrary (currently supported only on Linux and Windows).
# download URL for linux: https://github.com/Dao-AILab/flash-attention/releases # download URL for Windows: https://github.com/bdashore3/flash-attention/releases # install command: pip install *.whl
- Support for models Orion-14B-Chat, Orion-14B-LongChat and Orion-14B-Chat-Int4. To correctly load the model and perform inference, please install the
-
🚀 Update Log for 2024-04-14
- Support for the keras-llm-interpreter code interpreter, compatible with Windows, macOS, and Ubuntu operating systems. Provides locally executable binaries and Docker images for running in a sandbox environment.
- Support for models Qwen1.5-4B-Chat and Qwen1.5-7B-Chat.
-
🚀 Update Log for 2024-02-14
- Support for the open-interpreter code interpreter.
- Support for models gemma-2b and gemma-7b.
Anaconda download:(https://www.anaconda.com/download)
Git download:(https://git-scm.com/downloads)
CMake download:(https://cmake.org/download/)
Langchain Project: (https://github.com/langchain-ai/langchain)
Fastchat Project: (https://github.com/lm-sys/FastChat)