My awesome personal Machine Learning notes.
Part 1: Exploratory Data Analysis 👁️
| 🐼 | Pandas | The library for manage data. |  |
| ☝🏻 | Univariate analysis | Plot each variable independently. | |
| ✌🏻 | Bivariate analysis | Plot variable pairs. | |
| ❓ | Missings | Locate empty data. | |
| 🔎 | Outliers | Detect rare data. | |
| 👯 | Correlation | Find similar variables. | |
| 🌀 | Dimensionality reduction | See into 2 or 3 dimensions. |
Part 2: Prepare the data 🛠
| 🗃️ | Combine tables | Merge tables by forenig key. |  |
| ➕ | Feature engineering | Create new features. | |
| ➖ | Feature selection | Drop usless features. | |
| ✏️ | Encoding | Encode variables & deal with missings. | |
| ✂ | Split data | Define train and validation sets. | |
| 📊 | Imbalanced Data | Detect rare data. |
| 🔮 | Models: Prediction, Clustering | Select an appropriate model. |
| 🎯 | Hyperparameter optimization (HPO) | Optimize model hyperparameters. |
| 👪 | Ensemble | Use several models. |
| 📏 | Metrics: Classification, Regression | Measure the model performance. |
| 💭 | Interpretability (MLI) | Explain your model decisions |
| 🍹 | Auto Machine learning | Automatic machine learning pipeline |
| ⏫ | Model Deployment (API REST) | Deploy model as consumable software service. |
| 📋 | Model Monitoring (Logging) | Log and detect errors. |
| ♻️ | Model Maintenance (Retraining) | Retrain model on more recent data. |
| 🔒 | Security | Secure your model and avoid hacking (attacks) |

# Put this on top of your notebook
import gc
import numpy as np
import datatable as dt
import pandas as pd
import seaborn as sb
import pandas_profiling as pd_eda
import missingno as msno
import matplotlib.pyplot as plt
import altair as alt
from tqdm import tqdm_notebook as tqdm🐼 Pandas 🔝
- Import pandas library
import pandas as pd - Read a CSV file into a pandas dataframe
df = pd.read_csv("file.csv") - Get dataframe info:
- Show firt/last rows
df.head()df.tail() - Get shape:
df.shape. Get columns:df.columns.tolist(). - Print some info (like missings and types):
df.info() - Has missings?
df.isnull().any().any() - Describe numerical atributes
df.describe() - Describe categorical atributes
df.describe(include=['object', 'bool'])
- Show firt/last rows
- Do some data exploration
- Get some column (return a series)
df["column"] - Get some columns (return a df)
df[["column1", "column1"]] - Apply function to column
.mean().std().median().max().min().count() - Count unique values
.value_counts()
- Get some column (return a series)
- Filter dataframe rows
- One condition
df[df["column"]==1] - Multiple conditions
df[(df["column1"]==1) & (df["column2"]=='No')]
- One condition
- Save it in a CSV
df.to_csv("sub.csv", index=False)
df = pd.read_csv("data.csv")df.head() # Show the first 5 rows
df.tail() # Show the last 5 rows
df.sample(N) # Show N random rows
df.dtypes # Show features types
df.info() # Show features types and missings
df.describe() # Describe numeric features: count, mean, std, min, 25%, 50%, 75%, max
df.describe(include=['object', 'bool']) # Describe categoric features: count, unique, top, freq
df.profile_report() # Histograms, missings, correlations, etc (Pandas Profiling package)def reduce_mem_usage(df, verbose=True):
start_mem = df.memory_usage().sum() / 1024**2
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if np.iinfo(np.int8).min<c_min and c_max<np.iinfo(np.int8).max: df[col] = df[col].astype(np.int8)
elif np.iinfo(np.int16).min<c_min and c_max<np.iinfo(np.int16).max: df[col] = df[col].astype(np.int16)
elif np.iinfo(np.int32).min<c_min and c_max<np.iinfo(np.int32).max: df[col] = df[col].astype(np.int32)
elif np.iinfo(np.int64).min<c_min and c_max<np.iinfo(np.int64).max: df[col] = df[col].astype(np.int64)
else:
if np.finfo(np.float16).min<c_min and c_max<np.finfo(np.float16).max: df[col] = df[col].astype(np.float16)
elif np.finfo(np.float32).min<c_min and c_max<np.finfo(np.float32).max: df[col] = df[col].astype(np.float32)
elif np.finfo(np.float64).min<c_min and c_max<np.finfo(np.float64).max: df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
if verbose: print('Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)'.format(end_mem, 100*(start_mem-end_mem)/start_mem))
return df❓ Missing values 🔝
# Option 1: Pandas
def check_missing(df):
total = df.isnull().sum().sort_values(ascending=False)
percent = (df.isnull().sum()/df.isnull().count()*100).sort_values(ascending=False)
return pd.concat([total, percent], axis=1, keys=['Total', 'Percent missing'])
sns.heatmap(df.isnull(), cbar=False); # Option 2: With Seaborn
msno.matrix(df); # Option 3: With missingno🔎 Outlier Detection 🔝
- Standard Deviation
- Percentiles
- Isolation Forest: sklearn.ensemble.IsolationForest
- Remove
- Change to max limit
#Dropping the outlier rows with standard deviation
factor = 3
upper_lim = data['column'].mean () + data['column'].std () * factor
lower_lim = data['column'].mean () - data['column'].std () * factor
data = data[(data['column'] < upper_lim) & (data['column'] > lower_lim)]from sklearn.ensemble import IsolationForest
clf = IsolationForest(contamination=0.01, behaviour='new')
outliers = clf.fit_predict(df_x)
sns.scatterplot(df_x.var1, df_x.var2, outliers, palette='Set1', legend=False)# Put this on top of your notebook
import pandas as pd
import featuretools as ft
import category_encoders as ce
from sklearn.compose import ColumnTransformer🗃️ Combine tables 🔝
![]()
If you have several tables or 1 table with many rows per entity (user, product,...), you have to do deep feature synthesis with the featuretools library. However, if you only have a regular table with single row per entity, then featuretools won’t be necessary.
Imagine you have several tables:
tables = ft.demo.load_mock_customer()
customers_df = tables["customers"]
sessions_df = tables["sessions"]
transactions_df = tables["transactions"]
products_df = tables["products"]Therefore, you have relations between tables:
entities = {
"customers": (customers_df, "customer_id"),
"sessions": (sessions_df, "session_id", "session_start"),
"transactions": (transactions_df, "transaction_id", "transaction_time"),
"products": (products_df, "product_id")
}
relationships = [
# (primary_entity, primary_key, foreing_entity, foreing_key)
("products", "product_id", "transactions", "product_id"),
("sessions", "session_id", "transactions", "session_id"),
("customers", "customer_id", "sessions", "customer_id")
]Then you can create an entity set:
es = ft.EntitySet("customer_data", entities, relationships)
es.plot()
Finally you can create the final dataset on the target entity (sessions for example), for doing Machine Learning:
df, vars = ft.dfs(entities=entities, relationships=relationships, target_entity="sessions")➕ Feature Engineering 🔝
df["{} + {}"].format(var1, var2) = df[var1] + df[var2]
df["{} - {}"].format(var1, var2) = df[var1] - df[var2]
df["{} * {}"].format(var1, var2) = df[var1] * df[var2]
df["{} / {}"].format(var1, var2) = df[var1] / df[var2] # Precio del metro cuadrodo si tenemos metros y precio de la casa
df["log({})"].format(var1) = np.log(df[var1]) # Good for skewed (not normal distribution) data
df["log2({})"].format(var1) = 1+np.log(df[var1]) # Good for skewed (not normal distribution) data
df["root({})"].format(var1) = np.root(df[var1])
df["root2({})"].format(var1) = np.root(df[var1]+2/3)
df["square({})"].format(var1) = np.square(df[var1])
df["BoxCox({})"].format(var1) = # Box-Cox transform
#Binning: Fixed-Width (ej. age intervals) Good for uniform distributions
#Binning: Adaptive (quantile based): Good for skewed (not normal distribution) datadf["latitud"] = df["ciudad"].getLat()
df["longitud"] = df["ciudad"].getLon()
df["poblacion"] = df["ciudad"].getPob()
df["pais"] = df["ciudad"].getCou() # Cluster (Paris->France)# Simple
def featEng_date(df, varName):
df['year'] = df[varName].dt.year.astype(np.int16)
df['month'] = df[varName].dt.month.astype(np.int8)
df['week'] = df[varName].dt.weekofyear.astype(np.int8)
df['day_of_year'] = df[varName].dt.dayofyear.astype(np.int16)
df['day_of_month'] = df[varName].dt.day.astype(np.int8)
df['day_of_week'] = df[varName].dt.dayofweek.astype(np.int8)
df['hour'] = df[varName].dt.hour.astype(np.int8)
df['minute'] = df[varName].dt.minute.astype(np.int8)
df['is_weekend'] = # To do
df['is_vavation'] = # To do
# Advanced: Agregregates
periods = ["15T", "1H", "3H"]
agregates = ["count", "mean", "std", "min", "max", "sum", "median"]➖ Feature Selection 🔝
Boruta-py: all-relevant feature selection method (by scikit-learn contribution)
Reduce number of attributes. See feat importance, correlations...
- Mutual information
- LASSO
- Feature selection
- Wrapper: Su usa un classificador
- MultiObjectiveEvolutionarySearch: Mejor para muchas generaciones. 10000 Evals
- PSO: Particule Search optimization: Mejor para pocas generaciones.
- RFE: Recursive feature elimination
- SelectKBest
- Variance Threshold
- Filters:
- InfoGAIN: Cantidad de informacion
- Correlation Featue Selection
At each iteration, select one feature to remove until there are n feature left*
from sklearn.feature_selection import RFEThe SelectKBest class just scores the features using a function and then removes all but the k highest scoring features.
from sklearn.feature_selection import SelectKBestDrop all features that dont meet a variance threshold
from sklearn.feature_selection import VarianceThreshold🛠 Encoding 🔝
Categorical feats encoding in Trees
|
|
|
| Binary |
|
|
|---|---|---|
| Categorical Ordinal |
|
|
| Numerical |
|
|
from sklearn.compose import make_column_transformer
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import OrdinalEncoder
from sklearn.preprocessing import StandardScaler
################ Automatic detect types (dangerous)
# See data types: df.info()
num_cols = df.select_dtypes(exclude=[object,'datetime64','timedelta64']).columns # X.columns[X.dtypes == 'float64']
cat_cols = df.select_dtypes(include=[object]).columns # X.columns[X.dtypes == 'O']
time_cols = df.select_dtypes(include=['datetime64','timedelta64']).columns
# high_cardinality = [c for c in cat_cols if len(X[c].unique()) > 16]
# low_cardinality = [c for c in cat_cols if len(X[c].unique()) <= 16]
# num_uniques = int(df[var].nunique())
# embed_dim = int(min(num_uniques // 2, 50)
categories = [
X[column].unique() for column in X[cat_cols]]
for cat in categories:
cat[cat == None] = 'missing' # noqa
################ Tree-based models preprocessing
cat_proc_tree = make_pipeline(
SimpleImputer(missing_values=None, strategy='constant', fill_value='missing'),
OrdinalEncoder(categories=categories))
num_proc_tree = make_pipeline(
SimpleImputer(strategy='mean'))
prepro_tree = make_column_transformer(
(cat_proc_tree, cat_cols),
(num_proc_tree, num_cols),
remainder='passthrough')
################ Multiplicative-based models preprocessing
cat_proc_mult = make_pipeline(
SimpleImputer(missing_values=None, strategy='constant', fill_value='missing'),
OneHotEncoder(categories=categories)
)
num_proc_mult = make_pipeline(
SimpleImputer(strategy='mean'),
StandardScaler()
)
prepro_mult = make_column_transformer(
(cat_proc_mult, cat_cols),
(num_proc_mult, num_cols),
remainder='passthrough')
################ Some model examples
lasso = make_pipeline(prepro_mult, LassoCV())
rf = make_pipeline(prepro_tree, RandomForestRegressor(random_state=SEED))
gbm = make_pipeline(prepro_tree, HistGradientBoostingRegressor(random_state=SEED))
models = [('Random Forest', rf),
('Lasso', lasso),
('Gradient Boosting', gbm)]- Split (name & surname)
- Bag of words
- tfidf
- n-grams
- word2vec
- topic extraction
- Categorical-encoding: Categorical variables encoding (by scikit-learn contribution)
- FeatureHub:
- TO DO: What is Latent feature discovery ???
- Remove
- Rows with missings
df = df.loc[df.isnull().mean(axis=1) < 0.6]
- Columns with missings
- If has 1 missing:
df = df[df.columns[df.isnull().any()] - If has 70% (o more) of missings:
df = df[df.columns[df.isnull().mean() < 0.7]]
- If has 1 missing:
- Rows with missings
- Imputation:
- Univariate feature imputation: By looking only the missing column (
SimpleImputer)- Numeric:
meanormedian - Categoric:
most_frequentorconstant - But when Time Series:
interpolation
- Numeric:
- Bivariate feature imputation: By looking other columns and train a predictor (
IterativeImputer) ⭐
- Univariate feature imputation: By looking only the missing column (
Tips:
- Tip 1: Imputation + missing indicator: Note that if you are using a data imputation technique, you can add an additional binary feature as a missing indicator. GOOD PRACTICE
- Tip 2: Before you start working on the learning problem, you cannot tell which data imputation technique will work the best. Try several techniques, build several models and select the one that works the best.
######################################################################## Pandas
data = data.fillna(0) # Filling all missing values with 0
data = data.fillna(data.median()) # Filling missing values with medians of the columns
######################################################################## Sklearn SimpleImputer
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean', missing_values=np.nan, add_indicator=False)
imputer = SimpleImputer(strategy='median')
imputer = SimpleImputer(strategy='most_frequent')
imputer = SimpleImputer(strategy='constant')
imputed_X_train = pd.DataFrame(imputer.fit_transform(X_train))
imputed_X_valid = pd.DataFrame(imputer.transform(X_valid))
# Imputation removed column names; put them back
imputed_X_train.columns = X_train.columns
imputed_X_valid.columns = X_valid.columnsThe Iterative Imputer is developed by Scikit-Learn and models each feature with missing values as a function of other features. It uses that as an estimate for imputation. At each step, a feature is selected as output y and all other features are treated as inputs X. A regressor is then fitted on X and y and used to predict the missing values of y. This is done for each feature and repeated for several imputation rounds.
Let us take a look at an example. The data that I use is the well known Titanic dataset. In this dataset, the column Age has missing values that we would like to fill. The code, as always, is straightforward:
from sklearn.experimental import enable_iterative_imputer # explicitly require this experimental feature
from sklearn.impute import IterativeImputer
from sklearn.ensemble import RandomForestRegressor
# Load data
titanic = pd.read_csv("titanic.csv")
titanic = titanic.loc[:, ['Pclass', 'Age', 'SibSp', 'Parch', 'Fare']]
# Run imputer with a Random Forest estimator
imp = IterativeImputer(RandomForestRegressor(), max_iter=10, random_state=0)
titanic = pd.DataFrame(imp.fit_transform(titanic), columns=titanic.columns)The great thing about this method is that it allows you to use an estimator of your choosing. I used a RandomForestRegressor to mimic the behavior of the frequently used missForest in R.
- Additional tip 1: If you have sufficient data, then it might be an attractive option to simply delete samples with missing data. However, keep in mind that it could create bias in your data. Perhaps the missing data follows a pattern that you miss out on.
- Additional tip 2: The Iterative Imputer allows for different estimators to be used. After some testing, I found out that you can even use Catboost as an estimator! Unfortunately, LightGBM and XGBoost do not work since their random state names differ.
Some learning algorithms only work with numerical feature vectors. When some feature in your dataset is categorical, like “colors” or “days of the week,” you can transform such a categorical feature into several binary ones.
## One Hot Encoding takes a single categorical feature and converts it
## into several dummy columns
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
my_hot_encoded_dummy_cols = OneHotEncoder.fit_transform(my_cat_feature)# Binarizing
lb = preprocessing.LabelBinarizer()
lb.fit([1, 2, 6, 4, 2])
print(lb.transform((1,4)))
print(lb.classes_)- Scaling: Normalization: Numerical to range=[0, 1]
- Scaling: Standardization: Numerical to (mean= 0, std=1)
Normalization is the process of converting an actual range of values which a numerical feature can take, into a standard range of values, typically in the interval [−1, 1] or [0, 1]. For example, suppose the natural range of a particular feature is 350 to 1450. By subtracting 350 from every value of the feature, and dividing the result by 1100, one can normalize those values into the range [0, 1]. More generally, the normalization formula looks like this:
new_x = (x − min(x)) / max(x) − min(x)
Standardization is the procedure during which the feature values are rescaled so that they have the properties of a standard normal distribution with μ = 0 and σ = 1, where μ is the mean (the average value of the feature, averaged over all examples in the dataset) and σ is the standard deviation from the mean. Standard scores (or z-scores) of features are calculated as follows:
new_x = x − mean / standard deviation
## Standardization using pandas
df['var'] = ((df['var']-(df['var'].mean())))/(df['var'].std())## Standard Scaler - you should always fit your scaler on training data,
## then apply it to the test data
scaler = StandardScaler().fit(X_train)
X_train_1 = scaler.transform(X_train)
X_test_1 = scaler.transform(X_test)🌀 Dimensionality reduction 🔝
| Method | Name | Based in | Duration |
|---|---|---|---|
| PCA | Principal Component Analysis | Linear (maximize variance) | Fast |
| t-SNE | t Stochastic Neighbor Embedding | Neighbors | |
| LargeVis | LargeVis | Neighbors | |
| ISOMAP | t Stochastic Neighbor Embedding | Neighbors | |
| UMAP | Uniform Manifold Approximation and Projection | Neighbors | |
| AE | Autoencoder (2 or 3 at hidden layer) | Neural | |
| VAE | Variational Autoencoder | Neural | |
| LSA | Latent Semantic Analysis | ||
| SVD | Singular Value decomposition | Linear? | |
| LDA | Linear Discriminant Analysis | Linear | |
| MDS | Multidimensional Scaling |
Why reduce dimensions?
- Remove multicollinearity
- Deal with the curse of dimensionality
- Remove redundant features
- Interpretation & Visualization
- Make computations easier
- Identify Outliers
a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components. The first component is the most important one, followed by the second, then the third, and so on.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(X)Read How to use t-SNE effectively
from sklearn.manifold import TSNE
tsne = TSNE(random_state=0)
x_tsne = tsne.fit_transform(x)
# And plot it:
plt.scatter(x_tsne[:, 0], x_tsne[:, 1]);a statistical technique for revealing hidden factors that underlie sets of random variables, measurements, or signals.
a technique for analyzing multiple regression data that suffer from multicollinearity. The basic idea behind PCR is to calculate the principal components and then use some of these components as predictors in a linear regression model fitted using the typical least squares procedure.
PCR creates components to explain the observed variability in the predictor variables, without considering the response variable at all. On the other hand, PLSR does take the response variable into account, and therefore often leads to models that are able to fit the response variable with fewer components.
an algorithm that maps a high-dimensional space to a space of lower dimensionality by trying to preserve the structure of inter-point distances in high-dimensional space in the lower-dimension projection. sometimes we have to ask the question “what non-linear transformation is optimal for some given dataset”. While PCA simply maximizes variance, sometimes we need to maximize some other measure that represents the degree to which complex structure is preserved by the transformation. Various such measures exist, and one of these defines the so-called Sammon Mapping. It is particularly suited for use in exploratory data analysis.
a means of visualizing the level of similarity of individual cases of a dataset.
a type of statistical technique that involves finding the most “interesting” possible projections in multidimensional data. Often, projections which deviate more from a normal distribution are considered to be more interesting.
if you need a classification algorithm you should start with logistic regression. However, LR is traditionally limited to only two class classification problems. Now, if your problem involves more than two classes you should use LDA. LDA also works as a dimensionality reduction algorithm; it reduces the number of dimension from original to C — 1 number of features where C is the number of classes.
Mixture Discriminant Analysis (MDA) — It is an extension of linear discriminant analysis. Its a supervised method for classification that is based on mixture models.
Linear Discriminant Analysis can only learn linear boundaries, while Quadratic Discriminant Analysis is capable of learning quadratic boundaries (hence it is more flexible). Unlike LDA however, in QDA there is no assumption that the covariance of each of the classes is identical.
a classification model based on a mixture of linear regression models, which uses optimal scoring to transform the response variable so that the data are in a better form for linear separation, and multiple adaptive regression splines to generate the discriminant surface.
✂ Split data 🔝
- Simple split
- Cross validation
Split data into x, y for training and testing
from sklearn.model_selection import train_test_split
## make a train test split
X_train, X_test, y_train, y_test = train_test_split(X, y)Check: https://scikit-learn.org/stable/modules/cross_validation.html
📊 Imbalanced Data 🔝
- Solution
FIX IT ON DATA(Resample on train data)- Subsample majority class. But you can lose important data.
- Random:
from imblearn.under_sampling import RandomUnderSampler - Cluster Centroids:
from imblearn.under_sampling import ClusterCentroids - Tomek links:
from imblearn.under_sampling import TomekLinks
- Random:
- Oversample minority class. But you can overfit.
- Random:
from imblearn.over_sampling import RandomOverSampler - SMOTE
from imblearn.over_sampling import SMOTE - ADASYN
- SMOTENC: SMOTE for also categorial vars.
- Random:
- Combine both
- Tomek links & SMOTE:
from imblearn.combine import SMOTETomek
- Tomek links & SMOTE:
- Subsample majority class. But you can lose important data.
- Solution
FIX IT ON MODEL: Overweight the minirity classes (supportd by most SoTA models)- Neural nets: Weighted loss function
CrossEntropyLoss(weight=[…])
- Neural nets: Weighted loss function
- Solution
FIX IT ON PREDICTIONS- Output probabilities, and tune rounding threshold. Using 0.5 with imbalanced data is just wrong in general.



Synthetic Minority Oversampling Technique (SMOTE) is an oversampling technique used to increase the samples in a minority class. It generates new samples by looking at the feature space of the target and detecting nearest neighbors. Then, it simply selects similar samples and changes a column at a time randomly within the feature space of the neighboring samples.
The module to implement SMOTE can be found within the imbalanced-learn package. You can simply import the package and apply a fit_transform:
from imblearn.over_sampling import SMOTE, ADASYN, SMOTENC
X_resampled, y_resampled = SMOTE(sampling_strategy='minority').fit_resample(X, y)
X_resampled, y_resampled = SMOTE(sampling_strategy={"Fraud":1000}).fit_resample(X, y)
X_resampled = pd.DataFrame(X_resampled, columns=X.columns)As you can see the model successfully oversampled the target variable. There are several strategies that you can take when oversampling using SMOTE:
- 'minority': resample only the minority class;
- 'not minority': resample all classes but the minority class;
- 'not majority': resample all classes but the majority class;
- 'all': resample all classes;
- When dict, the keys correspond to the targeted classes. The values correspond to the desired number of samples for each targeted class.
I chose to use a dictionary to specify the extent to which I wanted to oversample my data.
Additional tip 1: If you have categorical variables in your dataset SMOTE is likely to create values for those variables that cannot happen. For example, if you have a variable called isMale, which could only take 0 or 1, then SMOTE might create 0.365 as a value.
Instead, you can use SMOTENC which takes into account the nature of categorical variables. This version is also available in the imbalanced-learnpackage.
Additional tip 2: Make sure to oversample after creating the train/test split so that you only oversample the train data. You typically do not want to test your model on synthetic data.
from sklearn.model_selection import StratifiedKFold
from imblearn.over_sampling import SMOTE
cv = StratifiedKFold(n_splits=5)
for train_idx, test_idx, in cv.split(X, y):
X_train, y_train = X[train_idx], y[train_idx]
X_test, y_test = X[test_idx], y[test_idx]
X_train, y_train = SMOTE().fit_sample(X_train, y_train)
...Put this on top of your notebook
# Data libraries
import numpy as np
import pandas as pd
import sklearn as skl
import xgboost as xgb
import lightgbm as lgb
import catboost as cgb
import h2o.automl as ml_auto
import yellowbrick as ml_vis
import eli5 as ml_exp
from tqdm import tqdm_notebook as tqdm🔮 Prediction models 🔝
- Linear Models: scikit-learn chapeter
- Decision Tree: scikit-learn chapeter
- Support Vector Machine: scikit-learn chapeter
- Ensemble methods: scikit-learn chapeter
Simple models. Good for starting point (baseline), understand the data, and create surrogate models of blackbox models.
| Interpretable Model | Linear | Monotone | Interaction | Task | |
|---|---|---|---|---|---|
| Linear Regression | Yes | Yes | No | regr | ⭐ |
| Logistic Regression | No | Yes | No | class | |
| Decision Tree | No | Some | Yes | class,regr | ⭐ |
| Decision Rules | |||||
| RuleFit | Yes | No | Yes | class,regr | |
| Naive Bayes | No | Yes | No | class | |
| K-Nearest Neighbors | No | No | No | class,regr |
| Model | Import | |
|---|---|---|
| DT | Decision Tree | from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor |
| RF | Random Forest | from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor |
| RF | Random Forest (RAPIDS) | from cuml.ensemble import RandomForestClassifier, RandomForestRegressor |
| ET | Extra (Randomized) Trees | from sklearn.ensemble import ExtraTreesClassifier, ExtraTreesRegressor |
| AB | AdaBoost | from sklearn.ensemble import AdaBoostClassifier, AdaBoostRegressor |
| GB | Gradient Boosting | from sklearn.ensemble import GradientBoostingClassifier, GradientBoostingRegressor |
| XGB | XGBoost | from xgboost import XGBClassifier, XGBRegressor |
| LGBM | LightGBM | from lightgbm import LGBMClassifier, LGBMRegressor |
| CB | CatBoost | from catboost import CatBoostClassifier, CatBoostRegressor |
| NGB | NGBoost | from ngboost import NGBClassifier, NGBRegressor |
| RGF | Regularized Greedy Forest | from rgf.sklearn import RGFClassifier, RGFRegressor |
| from rgf.sklearn import FastRGFClassifier, FastRGFRegressor |
XGBoost:
{
"learning_rate": [0.01, 0.1, 0.5],
"n_estimators": [100, 250, 500],
"max_depth": [3, 5, 7],
"min_child_weight": [1, 3, 5],
"colsample_bytree": [0.5, 0.7, 1],
}
LightGBM:
{
"learning_rate": [0.01, 0.1, 0.5],
"n_estimators": [100, 250, 500],
"max_depth": [3, 5, 7],
"min_child_weight": [1, 3, 5],
"colsample_bytree": [0.5, 0.7, 1],
}
RGF:
{
"learning_rate": [0.01, 0.1, 0.5],
"max_leaf": [1000, 2500, 5000],
"algorithm": ["RGF", "RGF_Opt", "RGF_Sib"],
"l2": [1.0, 0.1, 0.01],
}Target does not follow a Gaussian distribution. Wrap the lineal reg. with a function.
- Binary category: Logistic regression (add sigmoid) and Probit regression
- Many categories: Multinomial logistic regression and Multinomial probit regression
- ordinal data: Ordered probit regression
- Discrete count: Poisson regression
- Time to the occurrence of an event:
- Very skewed outcome with a few very high values (household income).
- Mixed Effects/Hierarchical GLM
The features interact:
- Adding interactions manually
Not linear:
- Feature tranformations (log, root, exp, ...)
- Feature categorization (new subfeatures)
- Generalized Additive Models (GAMs): Fit standard regression coefficients to dome variables and nonlinear spline functions to other variables.
A method in Linear Regression for estimating the unknown parameters by creating a model which will minimize the sum of the squared errors between the observed data and the predicted one (observed values and estimated values).
used to estimate real values (cost of houses, number of calls, total sales etc.) based on continuous variable.
used to estimate discrete values ( Binary values like 0/1, yes/no, true/false) based on given set of independent variable
adds features into your model one by one until it finds an optimal score for your feature set. Stepwise selection alternates between forward and backward, bringing in and removing variables that meet the criteria for entry or removal, until a stable set of variables is attained. Though, I haven’t seen too many articles about it and I heard couple of arguments that it doesn’t work.
a flexible regression method that searches for interactions and non-linear relationships that help maximize predictive accuracy. This algorithms is inherently nonlinear (meaning that you don’t need to adapt your model to nonlinear patterns in the data by manually adding model terms (squared terms, interaction effects)).
a method for fitting a smooth curve between two variables, or fitting a smooth surface between an outcome and up to four predictor variables. The idea is that what if your data is not linearly distributed you can still apply the idea of regression. You can apply regression and it is called as locally weighted regression. You can apply LOESS when the relationship between independent and dependent variables is non-linear.
???
An extension made to linear models (typically regression methods) that penalizes models (penalty parameter) based on their complexity, favoring simpler models that are also better at generalizing.
- L1 o LASSO: Least Absolute Shrinkage and Selection Operator. Good for feat selection
- L2 o RIDGE: For robustness
- Elastic Net:
- LARS: Least-Angle Regression
Its goal is to solve problems of data overfitting. A standard linear or polynomial regression model will fail in the case where there is high collinearity (the existence of near-linear relationships among the independent variables) among the feature variables. Ridge Regression adds a small squared bias factor to the variables. Such a squared bias factor pulls the feature variable coefficients away from this rigidness, introducing a small amount of bias into the model but greatly reducing the variance. The Ridge regression has one main disadvantage, it includes all n features in the final model.
Least Absolute Shrinkage and Selection Operator (LASSO). In opposite to Ridge Regression, it only penalizes high coefficients. Lasso has the effect of forcing some coefficient estimates to be exactly zero when hyper parameter θ is sufficiently large. Therefore, one can say that Lasso performs variable selection producing models much easier to interpret than those produced by Ridge Regression.
LogisticRegression(penalty='l1')Ccombines some characteristics from both lasso and ridge. Lasso will eliminate many features, while ridge will reduce the impact of features that are not important in predicting your y values. This algorithm reduces the impact of different features (like ridge) while not eliminating all of the features (like lasso).
Similar to forward stepwise regression. At each step, it finds the predictor most correlated with the response. When multiple predictors having equal correlation exist, instead of continuing along the same predictor, it proceeds in a direction equiangular between the predictors.
| CHAID | CART | ID3 | C4.5 and C5.0 | |
|---|---|---|---|---|
| Year | 1980 | 1984 | 1986 | 1993 |
| Handle numeric (<,>) | Yes | Yes | No | Yes |
| Handle categorical | Yes | No | Yes | Yes |
| Handle missings | Yes | |||
| Non-binary branches | No | No | Yes | |
| Handle classification | Yes | Yes | Yes | |
| Handle regressioon | No | Yes | ||
| Split method (class) | Chi-square | GINI index | Information Gain | Gain Ratio |
| In Sklearn | No | Yes | No | No |
| In Chefboost | Yes | Yes | Yes | Yes (C4.5) |
| Video theory | video | video | video | video |
| Video code (Chefboost) | video | video | video | video |
- In decissiopn trees, there is no need to normalize data.
- C4.5 en Weka se llama J48
- C5.0 está patentado, por eso no se ve en las librerias.
builds a tree top-down. It starts at the root and choose an attribute that will be tested at each node. Each attribute is evaluated through some statistical means in order to detect which attribute splits the dataset the best. The best attribute becomes the root, with its attribute values branching out. Then the process continues with the rest of the attributes. Once an attribute is selected, it is not possible to backtrack.
C4.5, Quinlan’s next iteration is a newer version of ID3. The new features (versus ID3) are: (i) accepts both continuous and discrete features; (ii) handles incomplete data points; (iii) solves over-fitting problem by bottom-up technique usually known as “pruning”; and (iv) different weights can be applied the features that comprise the training data. C5.0, the most recent Quinlan iteration. This implementation is covered by patent and probably as a result, is rarely implemented (outside of commercial software packages).
CART is used as an acronym for the term decision tree. In general, implementing CART is very similar to implementing the above C4.5. The one difference though is that CART constructs trees based on a numerical splitting criterion recursively applied to the data, while the C4.5 includes the intermediate step of constructing rule sets.
an algorithm used for discovering relationships between a categorical response variable and other categorical predictor variables. It creates all possible cross tabulations for each categorical predictor until the best outcome is achieved and no further splitting can be performed. CHAID builds a predictive model, or tree, to help determine how variables best merge to explain the outcome in the given dependent variable. In CHAID analysis, nominal, ordinal, and continuous data can be used, where continuous predictors are split into categories with approximately equal number of observations. It is useful when looking for patterns in datasets with lots of categorical variables and is a convenient way of summarizing the data as the relationships can be easily visualized.
scikit-learn/scikit-learn#13732
- Quilan (M5)
- Wang (M5P)
M5 combines a conventional decision tree with the possibility of linear regression functions at the nodes. Besides accuracy, it can take tasks with very high dimension — up to hundreds of attributes. M5 model tree is a decision tree learner for regression task, meaning that it is used to predict values of numerical response variable Y. While M5 tree employs the same approach with CART tree in choosing mean squared error as impurity function, it does not assign a constant to the leaf node but instead it fit a multivariate linear regression model.
- OneR: Learns rules from a single feature. OneR is characterized by its simplicity, interpretability and its use as a benchmark.
- Sequential covering: General procedure that iteratively learns rules and removes the data points that are covered by the new rule.
- Bayesian Rule Lists: Combine pre-mined frequent patterns into a decision list using Bayesian statistics.
- RIPPER
- M5Rules
- PART
- JRip
- FURIA (fuzzy)
Given a set of transactions, the goal is to find rules that will predict the occurrences of an item based on the occurrences of other items in the transactions.
- Apriori algorithm
- Eclat algorithm
- FP (Frequent Pattern) Growth
has great significance in data mining. It is useful in mining frequent itemsets (a collection of one or more items) and relevant association rules. You usually use this algorithm on a database that has a large number of transactions. For example, the items customers buy at a supermarket. The Apriori algorithm reduces the number of candidates with the following principle: If an itemset is frequent, ALL of its subsets are frequent.
the biggest difference from the Apriori algorithm is that it uses Depth First Search instead of Breadth First Search. In the Apriori algorithm, the element based on the product (shopping cart items 1, 2, 3, 3, etc.) is used, but in Eclat algorithm, the transaction is passed on by the elements (Shopping Cart 100,200 etc.).
helps perform a market basket analysis on transaction data. Basically, it’s trying to identify sets of products that are frequently bought together. FP-Growth is preferred to Apriori because Apriori takes more execution time for repeated scanning of the transaction dataset to mine the frequent items.
Instance and distances based. Utility To guess missing feature data. Utility 2: For reduce or clean the dataset.
The closeness of two examples is given by a distance function.
- Euclidean distance is frequently used in practice.
- Negative cosine similarity is another popular choice.
- Chebychev distance
- Mahalanobis distance
- Hamming distance
Algorithms:
- K Nearest Neighbors (KNN): Used in recommendation systems. k = 5, 10 or sqrt(Num samples).
- Weighted KNN: Closer samples are more imortant. Better than KNN.
- Fuzzy KNN: Sample pionts class labels are multiclass vetor (distance to class centroids).
- Parzen: Define a window size (with gaussian shape for ex.) and select those samples. (k would be variable).
- Learning Vector Quantization (LVQ)
- Self-Organizing Map (SOM)
- Locally Weighted Learning (LWL)
can be used for both classification and regression problems. KNN stores all available cases and classifies new cases by a majority vote of its K neighbors. Predictions are made for a new data point by searching through the entire training set for the K most similar instances (the neighbors) and summarizing the output variable for those K instances. For regression problems, this might be the mean output variable, for classification problems this might be the mode (or most common) class value.
A downside of K-Nearest Neighbors is that it hangs on to the entire training dataset. LVQ is an artificial neural network algorithm that allows you to choose how many training instances to hang onto and learns exactly what those instances should look like. If you discover that KNN gives good results on your dataset try using LVQ to reduce the memory requirements of storing the entire training dataset.
an unsupervised deep learning model, mostly used for feature detection or dimensionality reduction. It outputs a 2D map for any number of indicators. SOM differ from other artificial neural networks as it apply competitive learning as opposed to error-correction learning (like backpropagation with gradient descent), and in the sense that they use a neighborhood function to preserve the topological properties of the input space.
The idea behind this algorithm is that instead of building a global model for the entire function space, for each point of interest we build a local model based on neighboring data of the query point. For this purpose, each data point becomes a weighting factor which expresses the influence of the data point for the prediction. Mainly, data points that are in the close neighborhood to the current query point are receiving a higher weight than data points which are far away.
- Naive Bayes
- Gaussian Naive Bayes
- Multinomial Naive Bayes
- Averaged One-Dependence Estimators (AODE)
- Bayesian Belief Network (BBN)
- Bayesian Network (BN)
assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature (independence). Provides a way of calculating posterior probability P(c|x) from P(c), P(x) and P(x|c). Useful for very large data sets.
assumes that the distribution of probability is Gaussian (normal). For continuous distributions, the Gaussian naive Bayes is the algorithm of choice.
a specific instance of Naive Bayes where the P(Featurei|Class) follows multinomial distribution (word counts, probabilities, etc.). This is mostly used for document classification problem (whether a document belongs to the category of sports, politics, technology etc.). The features/predictors used by the classifier are the frequency of the words present in the document.
developed to address the attribute-independence problem of the naive Bayes classifier. AODE frequently develops considerably more accurate classifiers than naive Bayes with a small cost of a modest increase in the amount of computation.
a probabilistic graphical model (a type of statistical model) that represents a set of variables and their conditional dependencies via a directed acyclic graph (DAG). For example, a Bayesian network could represent the probabilistic relationships between diseases and symptoms. Given symptoms, the network can be used to compute the probabilities of the presence of various diseases. A BBN is a special type of diagram (called a directed graph) together with an associated set of probability tables.
the goal of Bayesian networks is to model conditional dependence, and therefore causation, by representing conditional dependence by edges in a directed graph. Using them, you can efficiently conduct inference on the random variables in the graph through the use of factors.
Hidden Markov models (HMM)
a class of probabilistic graphical model that give us the ability to predict a sequence of unknown (hidden) variables from a set of observed variables. For example, we can use it to predict the weather (hidden variable) based on the type of clothes that someone wears (observed). HMM can be viewed as a Bayes Net unrolled through time with observations made at a sequence of time steps being used to predict the best sequence of hidden states.
a classical machine learning model to train sequential models. It is a type of Discriminative classifier that model the decision boundary between the different classes. The difference between discriminative and generative models is that while discriminative models try to model conditional probability distribution, i.e., P(y|x), generative models try to model a joint probability distribution, i.e., P(x,y). Their underlying principle is that they apply Logistic Regression on sequential inputs. Hidden Markov Models share some similarities with CRFs, one in that they are also used for sequential inputs. CRFs are most used for NLP tasks.
- with liear kernel
- with RBF kernel: Very good one
To extend SVM to cases in which the data is not linearly separable, we introduce the hinge loss function: max (0, 1 − yi (wxi − b)).
Multiple kernel functions exist, the most widely used of which is the RBF kernel.
👪 Ensembles 🔝
- Read this post in medium
- Read KAGGLE ENSEMBLING GUIDE
- Read OOF Stacking vs Blending
- Read DESlib, a scikit-learn based library for ensembles.
Put model predictions together (columns), and for each sample (row) compute:
- Mode (aka majority vote): The most frequent value. Only for classification
- Arithmetic mean (aka mean or average):
- Geometric mean (aka gmean): Most robust to outliers than mean. ⭐ The best read this
- Harmonic mean (aka hmean):
- Quadratic mean
- Weighted versions
- Rank versions

aka Meta model or Super Learning) ⭐ The best
- READ THIS
- Usaully done with several DL models and the metamodels are catboost & xgboost and then average both.
- There is 3 types of stacking
- Holdout stacking: (aka Blending) Holdout validation
- OOF Stacking: The out-of-fold models predictions is used to generate the new data. ⭐⭐ (Andrés approach)
- Ensemble model selection (Caruana): Greedy method to add o remove models of your ensemble.
- Bagging (Bootstrapped Aggregation): Models by subsampling the data.
- Random Forest: Rows & atribs bagging + Decision tress classifier, regressor
- Extra Trees: classifier, regressor
- Bagging meta-estimator
- Boosting
Random forests provide an improvement over bagged trees by way of a random small tweak that decorrelates the trees. As in bagging, we build a number forest of decision trees on bootstrapped training samples. But when building these decision trees, each time a split in a tree is considered, a random sample of m predictors is chosen as split candidates from the full set of p predictors. The split is allowed to use only one of those m predictors.
Ways to interpret feature impact:
- Partial Dependency Plot
- Permute a single feature
- Keep track of information gains due to each features
- Keep track of traffic that passes by each value.
- Works great with heterogeneous data and small datasets (unlike neural nets). link1, link2, link3
- Tree depth from 3 to 6
- XGBoost, LightGBM, CatBoost 💪 Scikit-learn: classifier, regressor
🔮 Clustering models 🔝
Separate data in groups, useful for labeling a dataset.
- Knowing K
- K-Means
- k-Medians
- Mean-Shift
- Without knowing K
- DBSCAN: Density-Based Spatial Clustering of Applications with Noise.
Methods to determine best k:
- Elbow Method
- Gap Method - like elbow method, but comparing with uniform
- Silhouette Score - (b-a) / max(a,b) where:
- a is inter cluster distance,
- b is next-nearest cluster centroid
K means goal is to partition X data points into K clusters where each data point is assigned to its closest cluster. The idea is to minimize the sum of all squared distances within a cluster, for all clusters. A completely differerent algorithm than KNN (don’t confuse the two!).
one of several methods of hierarchical clustering. It is based on grouping clusters in bottom-up fashion. In single-linkage clustering, the similarity of two clusters is the similarity of their most similar members.
a variation of K means algorithm. The idea is that instead of calculating the mean for each cluster (in order to determine its centroid), we calculate the median.
it works similarly to K means except for the fact that the data is assigned to each cluster with the weights being soft probabilities instead of distances. It has the advantage that the model becomes generative as we define the probability distribution for each model.
does not partition the dataset into clusters in a single step. Instead it involves multiple steps which run from a single cluster containing all the data points to N clusters containing single data point.
a form of clustering in which each data point can belong to more than one cluster.
used to separate clusters of high density from clusters of low density. DBSCAN requires just two parameters: the minimum distance between two points and the minimum number of points to form a dense region. Meaning, it groups together points that are close to each other (usually Euclidean distance) and a minimum number of points.
the idea behind it is similar to DBSCAN, but it addresses one of DBSCAN’s major weaknesses: the problem of detecting meaningful clusters in data of varying density.
a Linear-algebraic model that factors high-dimensional vectors into a low-dimensionality representation. Similar to Principal component analysis (PCA), NMF takes advantage of the fact that the vectors are non-negative. By factoring them into the lower-dimensional form, NMF forces the coefficients to also be non-negative.
a type of probabilistic model and an algorithm used to discover the topics that are present in a corpus. For example, if observations are words collected into documents, to obtain the cluster assignments, it needs two probability values: P( word | topics), the probability of a word given topics. And P( topics | documents), the probability of topics given documents. These values are calculated based on an initial random assignment. Then, you iterate them for each word in each document, to decide their topic assignment.
####Gaussian Mixture Model (GMM) Its goal is to find a mixture of multi-dimensional Gaussian probability distributions that best model any input dataset. It can be used for finding clusters in the same way that k-means does. The idea is quite simple, find the parameters of the Gaussians that best explain our data. We assume that the data is normal and we want to find parameters that maximize the likelihood of observing these data.
- Time series: Sequence of values of some feature (obtained in constant time periods).
- Goal: Get the forecast (predict future values).
🎯 Hyperparameters optimization 🔝
| Method | Name | Type | Stars |
|---|---|---|---|
| GS | Grid Search | Parallel | |
| RS | Random Search | Parallel | |
| BO-GP | Bayesian Optimization with Gaussian Processes | Sequential BO | ⭐ |
| NM | Nelder-Mead Algorithm | ? | ⭐⭐ |
| TPE | Tree of Parzen Estimators | ? | ⭐⭐⭐ |
| HB | HyperBand | ? | ⭐⭐⭐ |
| BOHB | Bayesian Optimization and HyperBand | ? | ⭐⭐⭐ |
| Simulated Annealing | ? | ||
| GD | Gradient Descent | Sequential | |
| PSO | Particle Swarm optimization | Evolutionary | ⭐ |
| CMA-ES | Covariance Matrix Adaptation Evolutionary Etrategy | Evolutionary |
- Grid Search: Brute-force
- Random Search:
- Bayesian Optimization: Which surrogate?
- BO with Gaussian Processes
- BO with Bayesian Linear Regression
- BO with Bayesian Neural Networks
- BO with Random Forests
- BO with Boosting + quantile regression
- Tree of Parzen Estimators
- Population-based:
- Genetic programming (TPOT)
- Particle Swarm optimization (PSO)
- Covarianc matrix Adaptation evolution (CMA-ES)
- Hyperparameter Gradient Descent
- Probabilistic Extrapolation of Learning Curves: in order to do early stopping
- Multi-fidelity optimization:
- What is it?:
- Make training faster to evaluate sooner. (Subset of the data, fewer iterations or epochs)
- Avoid unnecesary bad trainings (Early stopping)
- Successive halving: Many models with tiny data fraction. Then pick up best and increase data. Similar to PSO
- HyperBand: Imporvement of Successive halving.
- BOHB: Combine Bayesian Optimization and Hyperband.
- What is it?:
- If you have access to multiple fidelities (make training faster and representative by some tricks):
- BOHP:
- Combines the advantages of TPE and HyperBand
- Python package:
hpbandsterorauto-sklearn
- BOHP:
- If you dont have access to multiple fidelities:
- Low-dim continuous params: BO-GP (e.g. Spearmint)
- High-dim, categorical, conditional: SMAC or TPE
- Puerly continuous, budget >10x dimensionality: CMA-ES
- Sklearn: GS, RS
- Optunity: GS, RS, NM, PSO and TPE
- Hyperopt: RS, TPE
- Optuna BO-GP
- GPyOpt: BO-GP
- BayesianOptimization: BO-GP
- skopt: (Scikit-Optimize)
- Grid Search: Search over a discrete set of predefined hyperparameters values.
- Random Search: Provide a statistical distribution for each hyperparameter, for taking a random value.
- Gradient Descent: Optimize hyperparameters using gradient descent.
- Evolutionary: Uses evolutionary algorithms to search the space of possible hyperparameters.
📏 Classification Metrics 🔝
Check:
- Hinge loss (like in SVM)
- Square loss (like in ridge regression)
- Logistic loss or cross-entropy (like in logistic regression)
- Exponential loss (like in boosting)
| Score | Description | Tip |
|---|---|---|
| Accuracy | # correctly predicted / # observations |
Highly interpretable |
| Precision | TP / TP + FP = TP / predicted possitives |
|
| Recall | TP / TP + FN = TP / actual possitives |
|
| Fβ Score | (1+β²) * (Prec*Rec)/(β²*Prec+Rec) |
|
| F05 | 1.25 * (Prec*Rec)/(0.25*Prec+Rec) |
Good when you want to give more weight to precision |
| F1 | 2 * (Prec*Rec)/(Prec+Rec) |
|
| F2 | 5 * (Prec*Rec)/(4*Prec+Rec) |
Good when you want to give more weight to recall |
| Dice | 2 * (Pred ∩ GT)/(Pred + GT) |
|
| Log loss | ||
| MCC | Matthews Correlation Coefficient | Represents the confusion matrix. Good for imbalanced |
| AUC | Area Under the roc Curve | Represent the ROC curve. |
| AUCPR | Area Under the precision-recall Curve | |
| MACROAUC | Macro average of Areas Under the roc Curves | Good for imbalanced data |
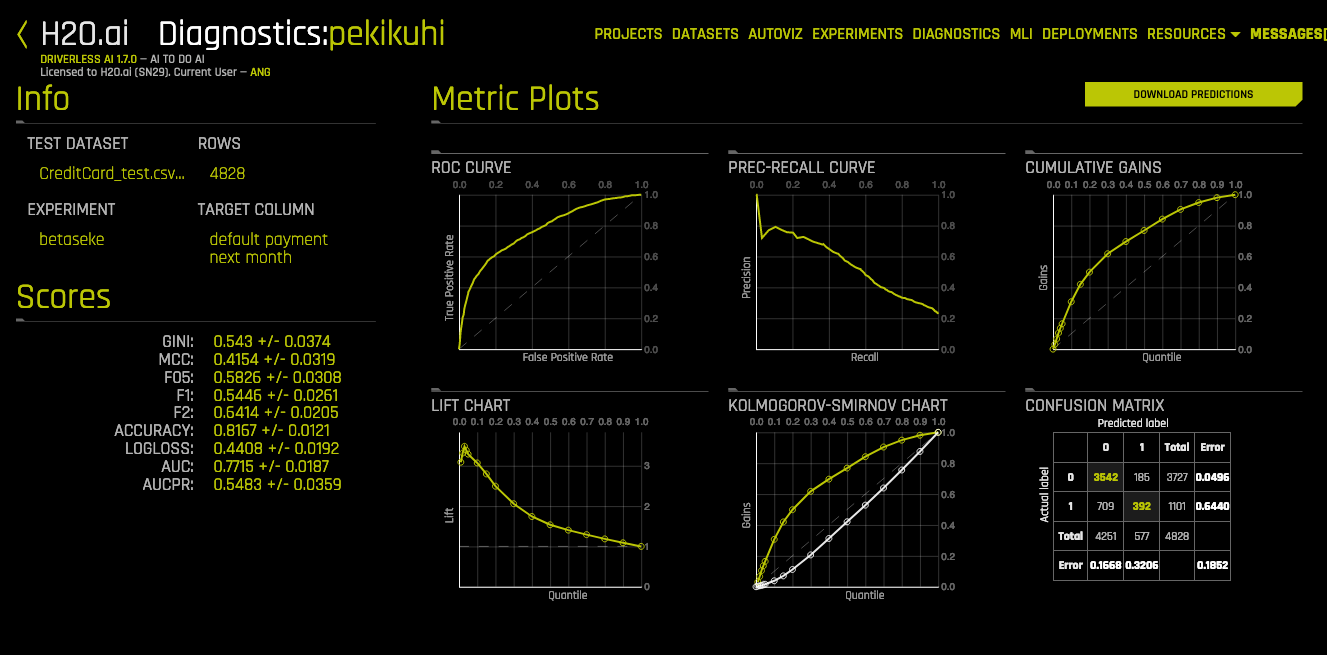
| Classification Metric Plots | |
|---|---|
| Confusion Matrix | ⭐ |
| ROC Curve | ⭐ |
| Precision-Recall Curve | |
| Cumulative Gains | |
| Lift Chart | |
| Kolmogorov-Smirnov Chart |
Dataset with 5 disease images and 20 normal images. If the model predicts all images to be normal, its accuracy is 80%, and F1-score of such a model is 0.88
📏 Regression Metrics 🔝
| Scores | Full name | Tip |
|---|---|---|
| ME | Mean Error (or Mean Bias Error) | It could determine if the model has positive bias or negative bias. |
| MAE | Mean Absolute Error | The most simple. |
| MSE | Mean Squared Error | Penalice large errors more than MAE. |
| MSLE | Mean Squared Log Error | |
| MPE | Mean Percent Error | Use when target values are across different scales |
| MAPE | Mean Absolute Percent Error | Use when target values are across different scales |
| SMAPE | Symmetric Mean Abs Percent Error | Use when target values close to 0 |
| MSPE | Mean Squared Percent Error | |
| RMSE | Root Mean Squared Error ⭐ | Proportional to MSE. |
| RMSLE | Root Mean Squared Log Error | Not penalize large differences when both values are large numbers. |
| RMSPE | Root Mean Squared Percent Error | Use when target values are across different scales |
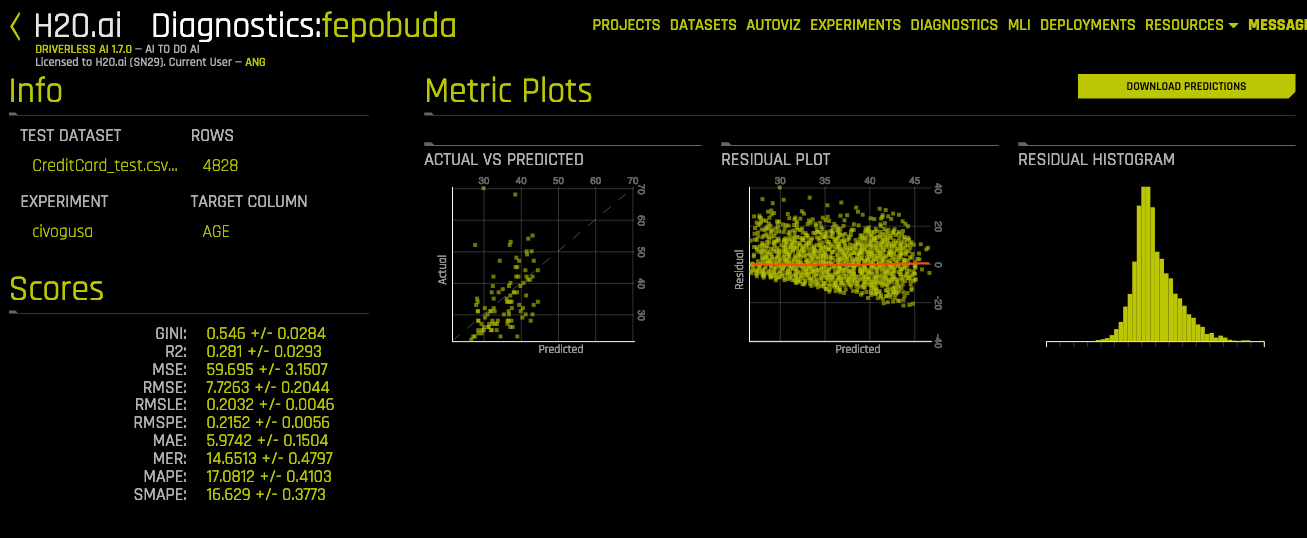
| R2 | R² (coefficient of determination) |
- Actual vs Predicted
- Residual Plot with LOESS curve
- Residual Histogram
💭 Interpretability 🔝
- h2o blog
- h2o doc
- THE BOOK
- explainerdashboard: A dashboard web app that explains the workings of a (scikit-learn compatible) ML model.
Good for:
- Detect social bias
- Model debugging
- Regulation
- Trust, transparency, in ML
Methods:
- Part 1: Interpletable models
- Decision tress
- GLMs
- Part 2: Black-box models interpletability
- LIME
- Shapley values
- Surrogate model
| Technique |
|---|
| 1. Global Shapley Feature Importance |
| 2. Global Original Feature Importance |
| 3. Partial Dependence |
| 4. Global Surrogate Decision Tree |
| 5. Global Interpretable Model |
| 6. Local Shapley Feature Importance |
| 7. Local Linear Explanations |
| 8. Local Surrogate Tree Decision Path |
| 9. Original Feature Individual Conditional Exception ICE |
| 10. Local Original Feature Importance |










⏫ Model Deployment 🔝
🔒 Security 🔝
Reference: Secure Machine Learning Ideas
- Data poisoning attacks
- Backdoors and Watermark attacks
- Surrogate Model Inversion attacks
- Membership inference by surrogate model
- Adversarial example attacks
- Impersonation

🍹 Auto Machine learning 🔝
- MLBox
- Auto Sklean
- TPOT ⭐
- H20 ⭐
- Neural Architecture Search (NAS) for deep learning
- DARTS: Differentiable Architecture Search
- Uber Ludwig ⭐
- Autokeras
- References
- DARTS: Differentiable Architecture Search paper, DARTS in PyTorch
🌍 Real world applications 🔝
- loss-given-default
- probability of default
- customer churn
- campaign response
- fraud detection
- anti-money-laundering
- predictive asset maintenance
- References
🗞️ Data sources 🔝
- Files
- CSV
- Excel
- Parquet (columnar storage file format of Hadoop)
- Feather
- Python datatable (.nff, .jay)
- No relational databases
- MongoDB
- Redis
- Relational Databases (SQL)
- MySQL
- Big data
- Hadoop (HDFS)
- S3 (Amazon)
- Azure Blob storage
- Blue Data Tap
- Google big query
- Google cloud storage
- kdb+
- Minio
- Snowflake
📊 Visualization 🔝
Libraries: Matplotlib and Seaborn
- Correlated Scatterplot
- Spikey Histograms
- Skewed Histograms
- Varying Boxplots
- Heteroscedastic Boxplots
- Biplot (PCA points and arrows)
- Outliers
- Correlation Graph
- Parallel Coordinates Plot
- Radar Plot
- Data Heatmap
- Missing Values Heatmap
- Gaps Histogram
- Univariate visualization
- Histogram
- Density plot
- Box plot
- Violin plot
- Bivariate visualization
- Multivariate visualization
- Parallel coords
- Radar chart
 |
 |
 |
 |
| Histogram | Density plot | Box plot | Violin plot |
| df.plot.hist() sns.distplot() |
df.plot.kde() sns.kdeplot() |
df.plot.box() sns.boxplot() |
sns.violinplot() |
 |
 |
 |
 |
 |
 |
| Scatter plot | Line plot | Bubble plot | Heatmap | Density plot 2D | Correlogram |
| df.plot.scatter() plt.scatter() sns.scatterplot() |
plt.imshow(np) sns.heatmap(df) |
df.plot.hexbin() | scatter_matrix(df) sns.pairplot() |
 |
 |
 |
 |
 |
| Bar plot | Lollipop plot | Parallel coords. | Radar chart | Word cloud |
| plt.scatter() sns.scatterplot() |
parallel_coordinates(df, 'cls') |
 |
 |
 |
 |
 |
 |
| Stacked bar plot | Pie chart | Donut chart | Dendrogram | Treemap | Venn diagram |
 |
 |
 |
 |
| Line chart | Area chart | Stacked area chart | Stream graph |
- Gaussian mixture models
- Prueba U de Mann-Whitney
- Prueba t de Student
- Metrica Kappa
- Self Organizing Map
- Restricted boltzmann machine: Como el autoencoder pero va y vuelve
- Competitive learning
- Hebbian learning
- Evolutionary algorithms
- Check Platypus
- Competitions
- Kaggle competitions: Participating in competitions is a great way to test your knowledge.
- Kaggle kernels: For each competition you have kernels (code notebooks) to code and learn.
- Kaggle discussion: For each competition you have discussions (forums) to read and learn.
- Courses
- Kaggle course: Practical micro-courses provided by Kaggle. (Level: easy)
- Fast.ai ML course: Course by Jeremy Howard, a DL teacher. (Level: easy)
- SaturdaysAI ML
- coursera-dl --download-quizzes --download-notebooks --subtitle-language "es,en" --video-resolution 720p -ca 'PONER_COOKIES_CAUTH' competitive-data-science
- Blogs
- FastML
- ML overview: (Level: easy)
- Maël Fabien blog: (Level: medium)
- Libraries documentation
- Scikit-learn documentation: (Level: hard)
- H2o driverless documentation: (Level: medium)
- Books
- The hundred-page machine learning book: (Level: medium) (This resource is not free)
- Interpretable Machine Learning: (Level: medium)
- The elements of statistical learning: (Level: hard)
- Data Visualization (Winner: Altair)
- Slides
- Post
- Notebooks
- Video
- Documentation
- Vega-embed (for frontend)
- Bayesian statistics:
- introduction to bayes the theorem
- video: Bayesian Statistics
- video: Bayesian Statistics with PyMC3
- Packages:
- Stan: Bayesian modeling
- PyMC3: Probabilistic programming
- ArviZ, Help us interpret and visualize posterior distributions of PyMC3
- Gaussian Process
- Gaussian mixture
- Dataframe databases comparison
- Feature engineering
- Vowpal Wabbit: