1.3 入门3文件下载_淘女郎照片
本节你可以学习到:如何下载文件,和调用子任务。因为已经有大众点评和链家教程的铺垫,本文章没有介绍详细的步骤,而重点介绍了加载工程,单步调试等功能。
哦?美女,那既然如此,我也用Hawk练练手,基本无需编程,直接无视动态js调用,下载高清图片。造福各位园友。这简直就是用Hawk做坏事啊~~
先看看抓取的效果,我才不直接放高清图呢!

在Hawk菜单->文件->加载工程,把project.xml加载进来。会是下面的样子:
然后,双击“主任务”加载这个任务。
之后任务就会被加载进来,在右下角显示所有的任务和数据表:
还会显示刚才从网上抓取的各种数据:
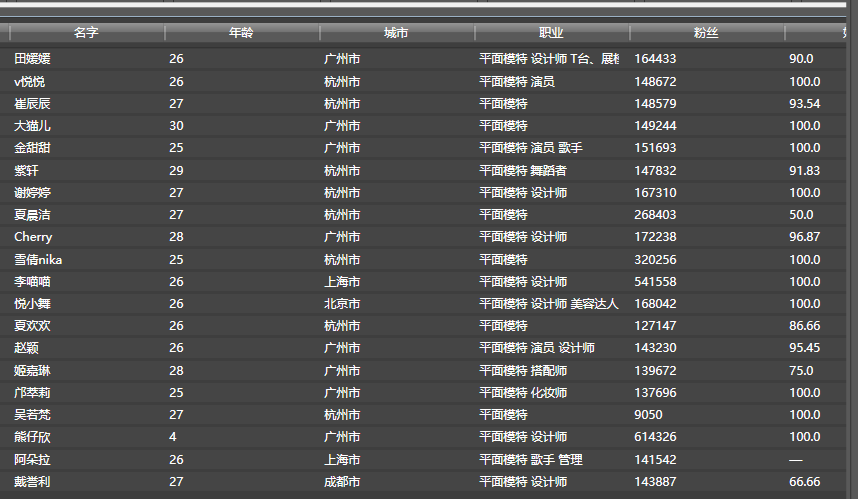
哈哈,不仅有详细的名字,地址,甚至还有身高体重等详细信息,各位慢慢看。
说好的保存图片呢?别急别急,这只是在模拟运行模式,保存图片这种有副作用的任务是不会执行的。
那我的图片保存在哪里了? //TODO:补充图片位置配置
之后,激动人心的时刻到了,在属性对话框点击执行:
然后,20个并行抓取任务线程就已经开始了:
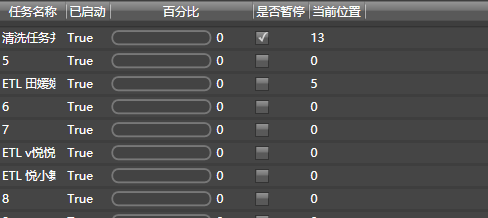
系统会自动维持线程列表中的线程数量,只有旧任务工作完毕后,才会添加新的线程进来。
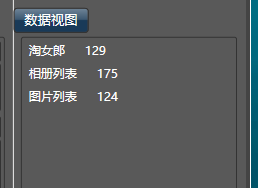
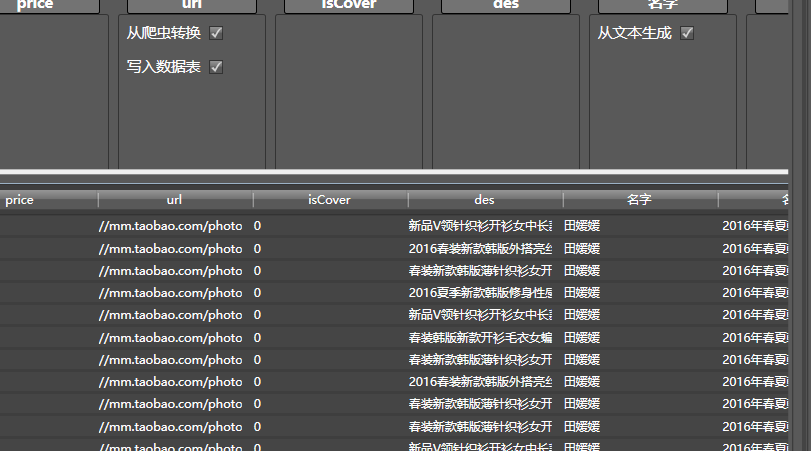
下面的三个表,分别是淘女郎信息表,相册信息表,和照片信息表。采集完毕后,你可以点右键,导出到excel,csv..
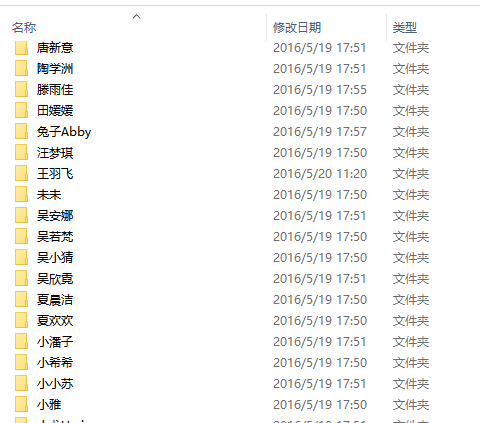
至于图片嘛,看看你设置的那个文件夹吧:
Enjoy!
Hawk本身是开源的,本质上是个编译和解释器。生成的xml就是代码和控制逻辑。很多个模块构成处理链条,你可以控制链条上的模块数量,就能观察数据是如何被采集和处理的。 整个程序包含两个流程:
- 主任务:负责从页面生成淘女郎的详细信息列表
- 相册:负责从淘女郎的id和姓名,获取其对应的照片。
先看主任务,我们勾选调试详情,点击播放器按钮,快退到第1步,之后向右点击下一步:
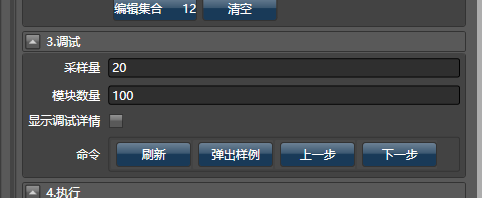
会有下面的信息显示出来,绿色代表该模块输入的列,蓝色代表输出的列。在调试模块属性中显示的是当前模块的基本信息和配置。
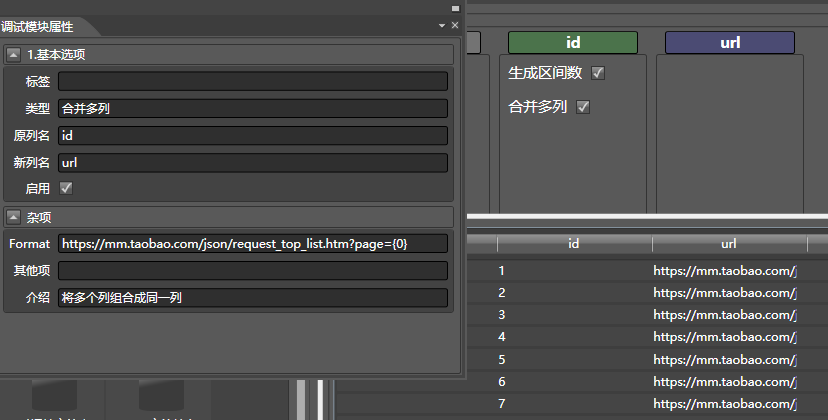
其基本的逻辑就是,生成从1到4700页的区间数,然后将它们分别转换成url:
然后通过从爬虫转换,获取女孩的列表,再根据用户的id,组合出详情页,并把详情页的信息附加到当前表。再将表的内容写入到“淘女郎”表,再针对每个女孩的id,去获取她的相册信息。
如果你直接双击相册模块,肯定是出现下面的情况,只有一个用户的数据:
//TODO:相册模块配置,
要想获取相册信息,需要拿到id和地址,怎么获得呢?
- 在本任务单独执行时,需要两个从文本生成来提供任务参数。
- 在主任务调用本任务时,
相册任务会读取主任务的id和名字两个列的内容,作为输入参数。
你也可以单步调试,看看这个模块是怎么获得的。基本流程如下:
- 通过女孩的id,组合出相册的url,比如下面:
mm.taobao.com/self/album/open_album_list.htm?_charset=utf-8&user_id%20=687471686
//TODO: 超级模式
- 通过一个网页采集器,名称为相册列表获取相册
- 再通过相册ID,获取相册的URL。相册的URL需要构造请求,获得的是Json。
- 把Json的头部Jsonp和末尾的括号去掉,形成正确格式的json
- 送入文本到Json转换模块,得到的是字典
- 使用Python转换器,提取里面的picList,再转换为文档列表。这就是照片列表
- 将路径和相册id,组合成实际要保存的图片的位置
- 加入保存超链接文件,会把指定url的文件保存到指定位置