The BabelNet-linker API allows a dictionary to be linked to BabelNet at definition level. Specifically, this API allows a definition in any language to be mapped to a semantically-equivalent English definition in BabelNet by relying on state-of-the-art Transformer-based architectures. Importantly, this API will make it possible to map the dictionaries made available within the ELEXIS Consortium at definition level by pivoting through BabelNet.
The present API is made up of the following three components:
- Model: This module contains the model used to perform cross-lingual dictionary linking.
- BabelNet: This module contains the code to obtain the BabelNet senses of a given lemma and POS tag. This module requires the BabelNet index.
- REST API: This module contains the code that will be used to obtain the dictionary senses from LEXONOMY of a given lemma and pos tag and communicate with the other two modules to perform the linking task.
The model is loaded when inference is performed on the pending requests. This is dealt with by the backend with a cronjob. More details are in the API section. For the docker container to access the model files, please place them in the model/ directory at the root of the project.
To download the model trained for the task, please visit the SapienzaNLP website.
We provide details about the models used in what follows.
The REST API requires access to definitions from BabelNet. It makes a request to an endpoint that returns all definitions, in English, for a given lemma, pos tag and language. The REST API expects the endpoint at http://192.168.1.91:9878, but it can be modified at:
BabelNet-linker/src/babelnet_calls.py
Lines 8 to 14 in 3bd34c8
There are different ways to set up an endpoint that returns the required with BabelNet. For more information see the BabelNet website.
The REST API uses python FastAPI, as well as a Pydantic model to validate the input, manage a database (sqlite) of the requests, and run them asynchronously. In fact, when a request is submitted, an ID is returned to the user, which can be used to check the status of the request. Once the request has been completed, the user can obtain the results using the ID.
This component is also dockerized. To build the container please run:
docker build -f dockerfiles/Dockerfile --build-arg MODEL_PATH="model" -t dict_api .
And then to run it:
PORT=12345
docker run -p $PORT:80 --name dict_api --gpus all dict_api
The port variable can be set to whatever is needed.
docker build -f dockerfiles/Dockerfile.cpu --build-arg MODEL_PATH="model" -t dict_api .
And then to run it:
PORT=12345
docker run -p $PORT:80 --name dict_api dict_api
The port variable can be set to whatever is needed.
To run the inference script we will need to run a cron job that will trigger the inference on the requests made that day:
docker exec dict_api bash -c 'python3 run_async.py'
As far as the models which we used to perform cross-lingual lexical resource linking, we devised two Transformer-based architectures, trained on our own curated datasets using BabelNet definitions. Such architectures are:
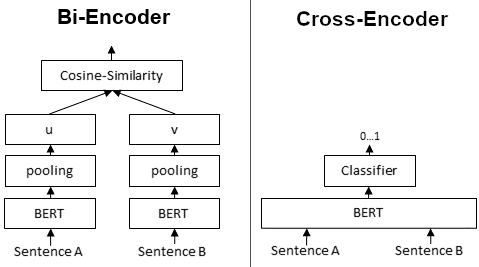
- Embedding based (Bi-encoder): This model is based on the embedding of two definitions independently, and the cosine similarity between them is used as the similarity score.
- Cross-encoder based: This model is based on the embedding of two senses using a cross-encoder, which receives as input the two definitions simultaneously, computing the similarity score with a Dense layer.
The embedding-based approach has the advantage of being able to compute the similarity score much faster, due to only encoding each definition once, ie. if there are N source senses and M target senses for a given lemma and pos tag, it only needs to encode N+M senses. However since it is based solely on the embeddings independently, there is no interaction between the two definitions.
The cross-encoder on the other hand is slower to compute since it has to encode both definitions simultaneously, ie. if there are N source senses and M target senses for a given lemma and pos tag, it will have to encode N*M inputs. However, it is able to compute the similarity score between the two definitions as input, leading to a better performance, which is the main advantage of this approach.
Instead of BERT we used multilingual encoders that have been pretrained on NLI tasks:
The model is trained on a binary task which consists in determining whether a given pair of definitions belong to the same synset. This is different than the evaluation at inference time. Here, the model is only given a pair and the loss is computed based on the similarity score between the two definitions in a binary fashion.
On the other hand, when evaluating the model, we are given a single definition in a source language, and we have to link it to the corresponding definition (synset) from BabelNet. Furthermore, we may have negative instances where we do not have a definition in the target language, for which the model should give a low score to all the candidate definitions. Performance is therefore based on this setup, for which we have positive and negative examples. We report Accuracy, Precision, Recall, and F1-Score, as well as Accuracy on the positive examples (ie. the ones that have a definition in the target language).
For training and validation purposes, we used two different datasets. The first one is based on BabelNet and uses already linked resources (i.e. WordNet and Wikipedia) in different languages to create positive and negative examples. This dataset was created in the following languages: Basque, Bulgarian, Danish, Dutch, English, Estonian, French, German, Hausa, Hungarian, Irish, Italian, Portuguese, Russian, Slovak, Slovene and Spanish. The second dataset comes from the Monolingual Word Sense alignment (MWSA) and serves as additional data to train the model and aims at domain adaptation since the BabelNet dataset uses definitions from a few determined sources.
For testing purposes, we used a manually-curated dataset in the following languages: Bulgarian, Danish, Estonian, Hungarian, Irish, Italian, Portuguese, Slovenian and Spanish.