-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
170 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,170 @@ | ||
| --- | ||
| title: 【技术角度折腾 xlog】更顺畅的发布体验 1可行性探索 | ||
| slug: play-xlog-01 | ||
| tags: | ||
| - xlog | ||
| update_time: 2023/10/15 23:21:36 | ||
| create_time: 2023/10/13 20:51:10 | ||
|
|
||
| --- | ||
|
|
||
|
|
||
|
|
||
|
|
||
| 想写个系列文章,从技术角度折腾地球上最好的 blog 平台 [xlog.app](https://xlog.app), 争取做到以下事情(开始夸海口了,新朋友,这是我的一种表达风格哈): | ||
| - 坚守心爱的文本编辑器,不离开 obsidian,一样发布 xlog 博客 | ||
| - 不开网页,依然可以访问 xlog ,阅读其他人的博客 | ||
| - 同步 xlog 博客,用自己的域名和服务器展示自己的内容 | ||
| - github + xlog = 多租户cms | ||
| - 成为 xlog 成员 | ||
|
|
||
| 口嗨完毕,开始尝试技术的可行性探索。本次内容我们来谈,如何通过官方提供的 openapi 访问 xlog 内容。 | ||
|
|
||
| ## 需求背景 | ||
|
|
||
| xlog 作为地球上最好的 blog 平台,有一个小问题,国内大陆访问可能会稍慢。全量迁移博客到 xlog 之后,自己的服务器就闲置了。 | ||
|
|
||
| 或者干脆一点,能不能拿在 xlog 上发布文章,自己部署一份儿?展望后面,谁说 xlog.app 才是访问 xlog 的唯一方式,我们是不是限制了 xlog 成为地球上最好的 headlessCMS 的潜力? | ||
|
|
||
| 那么开搞。 | ||
|
|
||
| ## 技术探索 | ||
|
|
||
| 从目前公开的信息来看,xlog 官方提供了多重方式获取 xlog 内容,以访问自己的数据为例: | ||
| - 可以通过 `crossbell` SDK 访问数据 | ||
| - 可以通过 http restful API 访问数据 | ||
|
|
||
| 接下来我们通过两种方式分别访问自己的数据,当然是已发布的公开文章。 | ||
|
|
||
| ### 前置准备 | ||
|
|
||
| 看下面的内容的大前提是,你需要是 xlog 的用户,没有的快去注册吧。 | ||
|
|
||
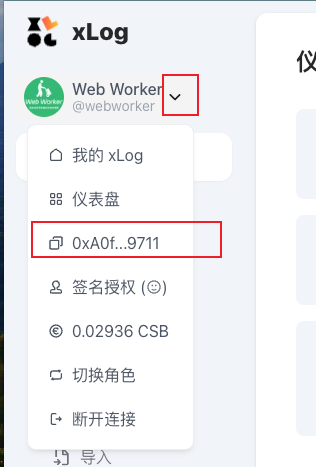
| 获取公开的地址 Address,访问 https://xlog.app/dashboard ,按照图片圈选位置,点击,会提示 【已复制】,可以把这个视为当前用户在 xlog 上的唯一 ID。如果你有多个角色,ID 是不同的。 | ||
|
|
||
| 我们找个小本本把他记录上,以我的为例,后续使用它来访问: `0xA0fb033D4849b13A16690EEbdd575Dd90bF29711` | ||
|
|
||
|  | ||
|
|
||
|
|
||
| 接下来我们使用不同的方式获取数据。 | ||
| ### 通过 SDK 访问数据 | ||
|
|
||
| 这里需要自备 Node.js 环境,如果你是非 Node 技术栈,直接看下面 通过官方 API 访问章节 | ||
|
|
||
| 官方 SDK 的 Github 地址 https://github.com/Crossbell-Box/crossbell.js | ||
|
|
||
| 吐槽:官方的文档不是很好,回头给他贡献修改下。 | ||
|
|
||
| 看我的吧。我们先使用只读用户访问数据。这里对应官方文档的 [Class Indexer](https://crossbell.js.org/classes/Indexer.html) | ||
|
|
||
|
|
||
| 首先启动项目 | ||
|
|
||
| ```shell | ||
| mkdir xlog-api-demo | ||
| cd xlog-api-demo && pnpm init | ||
| pnpm i crossbell | ||
| # 准备 ts 环境 | ||
| pnpm i typescript tsx -D | ||
| touch index.ts | ||
| ``` | ||
|
|
||
| 我们在 `index.ts` 中组织下面代码 | ||
|
|
||
| ```ts | ||
| import { createIndexer } from "crossbell"; | ||
|
|
||
| const indexer = createIndexer(); | ||
| const Address = process.env.USER_ADDRESS as `0x${string}`; | ||
|
|
||
| const getUserByAddress = async () => { | ||
| const res = await indexer.character.getMany(Address); | ||
|
|
||
| console.log(res); | ||
| }; | ||
| getUserByAddress(); | ||
|
|
||
| ``` | ||
|
|
||
| 具体执行,看对应的仓库,主要是根据 address 获取角色信息。可以获取 metadata 和 charactorId | ||
|
|
||
| ```ts | ||
| // const characterId = 53710; | ||
| const getNotesByCharacterId = async (characterId: number) => { | ||
| const res = await indexer.note.getMany({ | ||
| characterId, | ||
| includeNestedNotes: false, | ||
| limit: 10, | ||
| }); | ||
| console.log(res); | ||
| }; | ||
| ``` | ||
|
|
||
| 这个就可以读取到用户的数据了。 | ||
|
|
||
| 翻页可以通过 total + cursor + limit 实现, 游标 cursor 在每次请求结果中体现 | ||
|
|
||
| 查询具体详情,可以通过这个实现 | ||
|
|
||
| ```ts | ||
| const noteId = 16; | ||
| const characterId = 53710; | ||
| const getNoteById = async (noteId: number) => { | ||
| const res = await indexer.note.get(characterId, noteId); | ||
| // console.log(res); | ||
| console.log(res?.metadata?.content); | ||
| }; | ||
| getNoteById(noteId); | ||
| ``` | ||
|
|
||
| 类推其他方法,这里不一一列举,可以实现各类数据的展示。 | ||
|
|
||
| 通过以上两个方法,我们可以实现个人博客的搭建了,首页网站基础信息、列表页更新列表、详情页信息展示。 | ||
|
|
||
| 这里有两个细节,提一下: | ||
| - 自定义的 embed,比如音视频,需要自己兼容,这个有机会留到后面处理 | ||
| - 图片和链接全程用的 ipfs,这里展开说下 | ||
|
|
||
| ### ipfs 协议 | ||
|
|
||
| ipfs 协议包罗万物,简单说就是一串 hash,或者 cid 对应一个网络资源,细节不展开,对 web 来说 ipfs 并不是 http 协议,要展示图片,需要有一层协议转换的过程,这里面就涉及到 api 网关的解析。 | ||
|
|
||
| 这一块,一开始我是翻源码自己找到了 gateway ,后来返现好像不用特别 geek,访问 https://crossbell-ipfs-utils.vercel.app/img/bafkreiarfgti3xpv2oznl7rzanfbzm7gvklvcwn5poqb53wlhi3n4cwp2a 这个网页,这个网页从不同的 gateway 加载图片,你选择一个顺眼的就可以 | ||
|
|
||
|  | ||
|
|
||
| 注意,为了更快的加载速度,如果你考虑子托管,显然自己处理资源是最好的。 | ||
|
|
||
| 另外,xlog 有专门的保处理这个问题,可以作为编程方案使用,做个备忘 | ||
|
|
||
| ```ts | ||
| import { ipfsFetch } from "@crossbell/ipfs-fetch"; | ||
| ipfsFetch(ipfsUrl) | ||
| .then((res) => { | ||
| console.log(1, res); | ||
| }) | ||
| .catch((err) => { | ||
| console.log(3, err); | ||
| }); | ||
| ``` | ||
|
|
||
| 细节就谈这么多,更多的交互翻一翻 api 就好了。 | ||
|
|
||
| ### 通过官方 API 访问 | ||
|
|
||
| 刚才的技术方案依赖 Node.js,如果你擅长其他语言,或者想足够简单,官方还提供了 api,通过 restful api 进行交互,侵入性更低。 | ||
|
|
||
| 直接访问 | ||
|
|
||
| https://indexer.crossbell.io/docs | ||
|
|
||
| 按照 SDK 里提到的 address 作为入口 | ||
| - 访问 Character 第一个 Get characters of an address 获取 characterId `/v1/addresses/{address}/characters` | ||
| - 访问 Get a character by characterId 获取用户基础信息,给首页使用 `/v1/characters/{characterId}` | ||
| - 待补充 | ||
|
|
||
|
|
||
| 通过以上访问,依然可以实现和 sdk 一样的效果。 | ||
|
|
||
| 接下来,我们会继续探索,如果通过 sdk/api 实现后台管理,除了读取内容,我们还希望可以对文章进行增删改查,实行另一个 xlog。 |