Execution Layer
All code related to the backend layer are located inside cerebro.backend package. Cerebro currently supports only Spark as the execution backend. The execution backend integrates with one of the storage layers and provides the following features:
- Materializing training data: e.g., Writing the (pre-proceesed) training data in Spark DataFrames into HDFS storage.
- Implement model hopper parallelism.
Details on how training data materialization happens are provided in the storage layer details. We next provide more details on the model hopper parallelism implementation in the Spark backend.
Model hopper parallelism requires running multiple workers that perform sub-epoch training and a driver program that orchestrates the scheduling of sub-epochs on workers.
In the spark backend, workers are implemented as long running services that get invoked inside long-running map paritition functions in Spark. We create a dummy RDD with number of partions set to the number of workers needed for Cerebro and use that to invoke the map partition function. After the initiation, these services register with the Cerebro driver by providing service host and port number. Cerebro driver also runs a service for this registration purpose which runs in the same machine where Spark driver runs. Cerbro services can be intialized by calling the .initialize_workers() method of the Spark backend object.
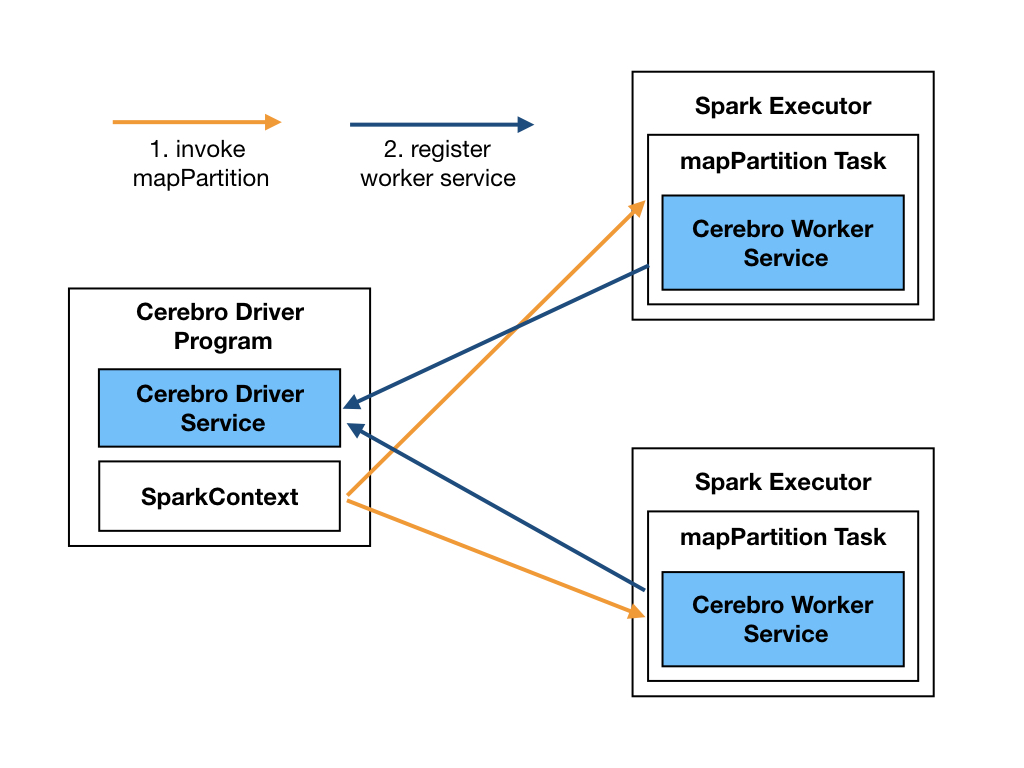
Cerebro worker service in Spark is cable of performing the following tasks:
- Initialize data loaders: This method initializes the Petastorm training and validation data loaders for the model selection workload. It should be done once upfront for every model selection workload. After the intialization, data loaders will be cached and reused for all sub-epoch trainings.
- Execute sub-epoch: This method invokes the training of a single sub-epoch. The training procedure is wrapped inside serialized function and send to the service as a parameter. The service deserializes the function and runs it locally. All model training aspects including model initialization, checkpoint restoring, and checkpoint creation are handled by this function. The Cerebro service is agnostic to the details of how model training works. It just invokes the provided trainer function by passing the initialized data loaders as input.
- Teardown service: This method stops the running service and finishes the encapsulating map partition function.
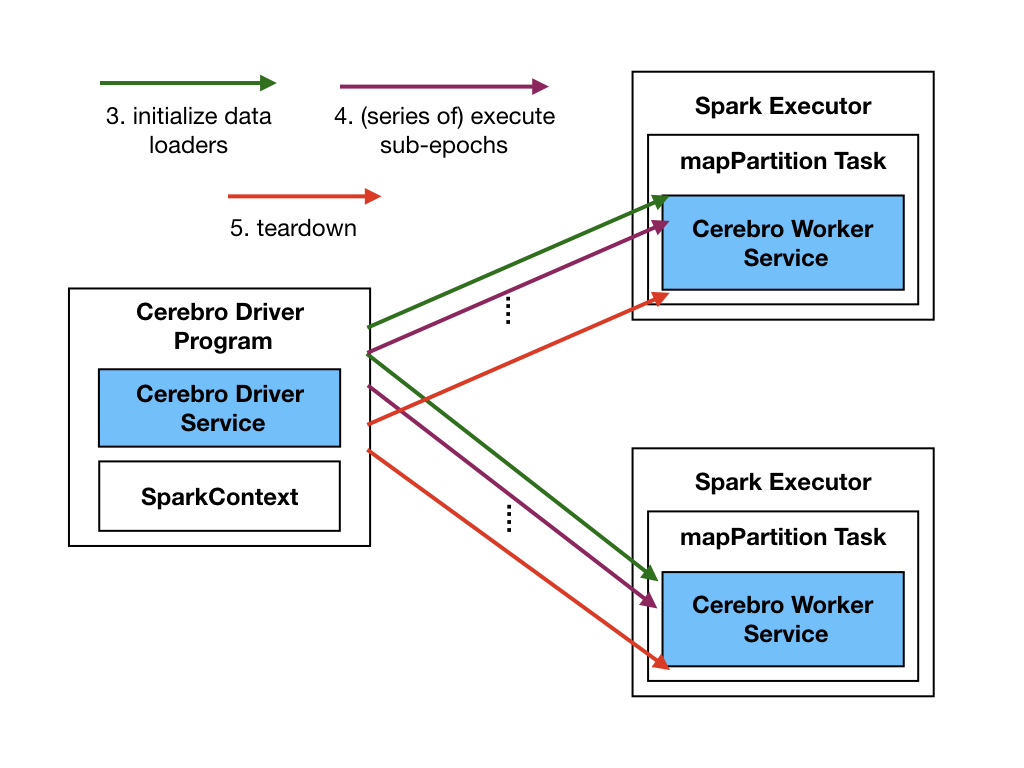
Spark backend implementation uses the above methods supported by the worker service to implement model hopper paralleism. It provides a per-epoch based scheduling functionality (.train_for_one_epoch(...)) to the higher-level model selection APIs. Essentially, it takes in a set of model configurations to be trained and completes one epoch of training for all models by invoking the required sub-epochs subjected to scheduling constraints. Finally, it returns the training metrics of the models (e.g., loss, accuracy) back to the caller.
In order to add support for a new execution backend, one has to implement a new class extending the Backend class.