diff --git a/docs/.vuepress/config.js b/docs/.vuepress/config.js
index 0ae3860d..b463cea6 100755
--- a/docs/.vuepress/config.js
+++ b/docs/.vuepress/config.js
@@ -2187,6 +2187,7 @@ function getBarBigMarket() {
children: [
"extra/big-market-v1.md",
"extra/big-market-v2.md",
+ "extra/big-market-v3.md",
]
}
]
diff --git a/docs/.vuepress/public/images/article/project/big-market/big-market-v3-01.gif b/docs/.vuepress/public/images/article/project/big-market/big-market-v3-01.gif
new file mode 100644
index 00000000..ef1cf805
Binary files /dev/null and b/docs/.vuepress/public/images/article/project/big-market/big-market-v3-01.gif differ
diff --git a/docs/.vuepress/public/images/article/project/big-market/big-market-v3-02.png b/docs/.vuepress/public/images/article/project/big-market/big-market-v3-02.png
new file mode 100644
index 00000000..f785dd89
Binary files /dev/null and b/docs/.vuepress/public/images/article/project/big-market/big-market-v3-02.png differ
diff --git a/docs/.vuepress/public/images/article/project/big-market/big-market-v3-03.png b/docs/.vuepress/public/images/article/project/big-market/big-market-v3-03.png
new file mode 100644
index 00000000..e5d05ca9
Binary files /dev/null and b/docs/.vuepress/public/images/article/project/big-market/big-market-v3-03.png differ
diff --git a/docs/.vuepress/public/images/article/project/big-market/big-market-v3-04.png b/docs/.vuepress/public/images/article/project/big-market/big-market-v3-04.png
new file mode 100644
index 00000000..81bcef19
Binary files /dev/null and b/docs/.vuepress/public/images/article/project/big-market/big-market-v3-04.png differ
diff --git a/docs/.vuepress/public/images/article/project/big-market/big-market-v3-05.png b/docs/.vuepress/public/images/article/project/big-market/big-market-v3-05.png
new file mode 100644
index 00000000..75e4426e
Binary files /dev/null and b/docs/.vuepress/public/images/article/project/big-market/big-market-v3-05.png differ
diff --git a/docs/md/project/big-market/extra/big-market-v2.md b/docs/md/project/big-market/extra/big-market-v2.md
index fa3fe4ea..aa7b0f97 100644
--- a/docs/md/project/big-market/extra/big-market-v2.md
+++ b/docs/md/project/big-market/extra/big-market-v2.md
@@ -10,7 +10,7 @@ lock: no
>沉淀、分享、成长,让自己和他人都能有所收获!😄
-大家伙,我是技术UP主,小傅哥。
+大家好,我是技术UP主,小傅哥。
清明假期即将来临,卷王的✋🏻手已经👨🏻💻 准备好啦!星球「码农会锁」第8个实战项目,《大营销平台系统》第1阶段用最基本技术栈引导小白入门,第2阶段将引入全体系的分布式技术栈,进行设计实现。—— 你们面试不总缺少分布式技术栈嘛,这回它来啦!😄
diff --git a/docs/md/project/big-market/extra/big-market-v3.md b/docs/md/project/big-market/extra/big-market-v3.md
new file mode 100644
index 00000000..b4f228c2
--- /dev/null
+++ b/docs/md/project/big-market/extra/big-market-v3.md
@@ -0,0 +1,164 @@
+---
+title: 第二阶段启动,分布式架构进行70%
+lock: no
+---
+
+# 《大营销平台系统》第二阶段启动,分布式架构进行70%
+
+作者:小傅哥
+
博客:[https://bugstack.cn](https://bugstack.cn)
+
+>沉淀、分享、成长,让自己和他人都能有所收获!😄
+
+
+
+大家好,我是技术UP主,小傅哥。
+
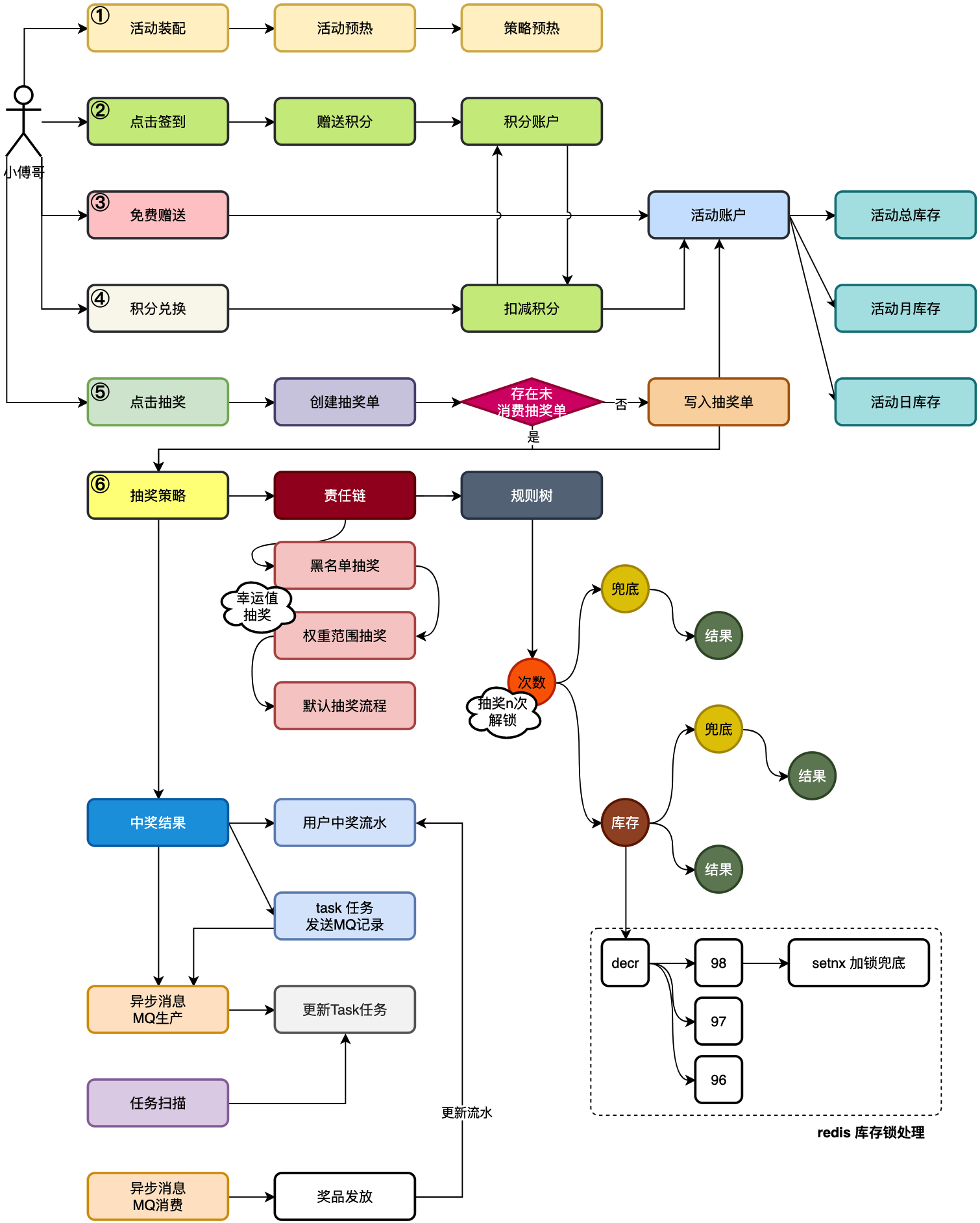
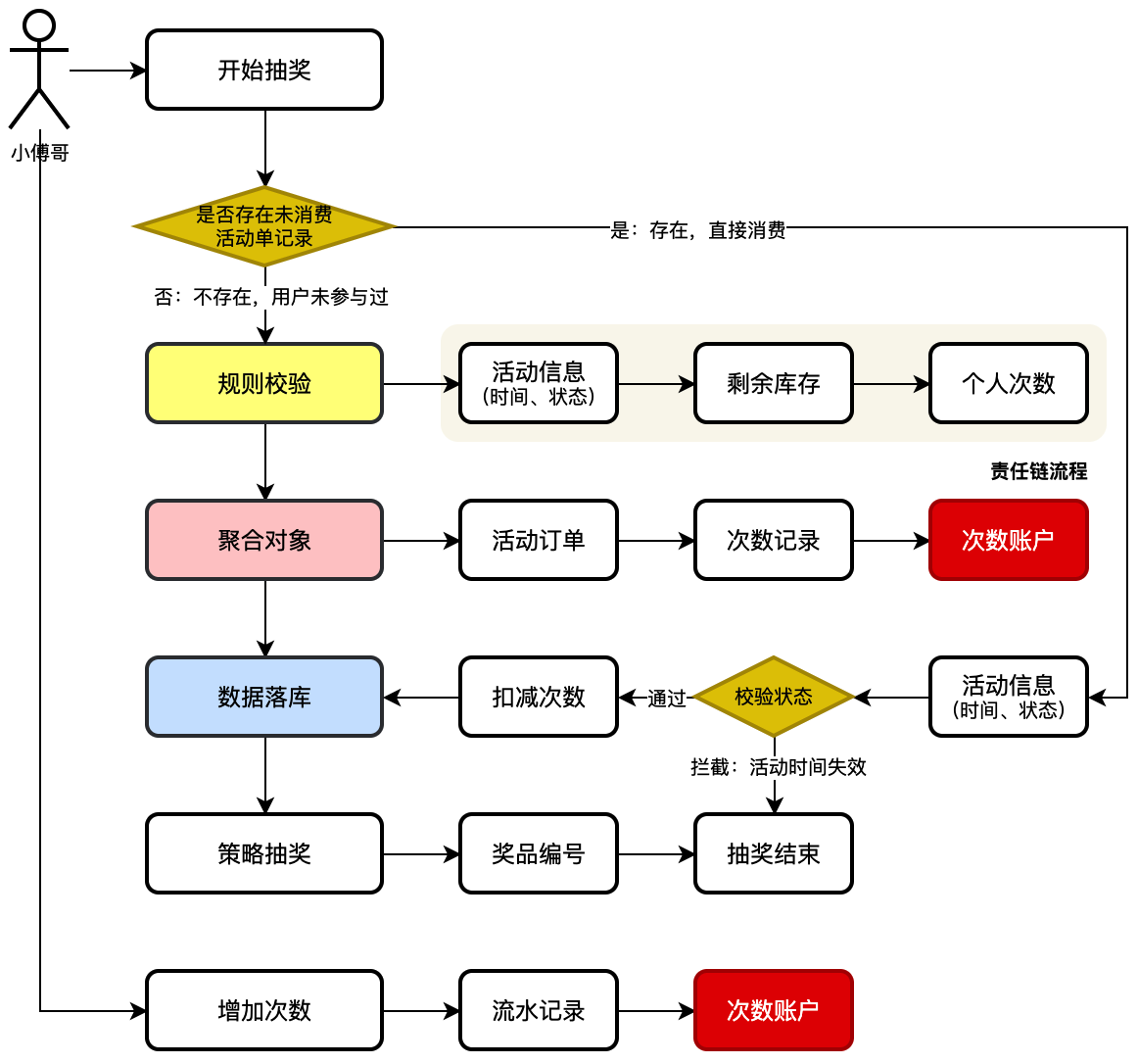
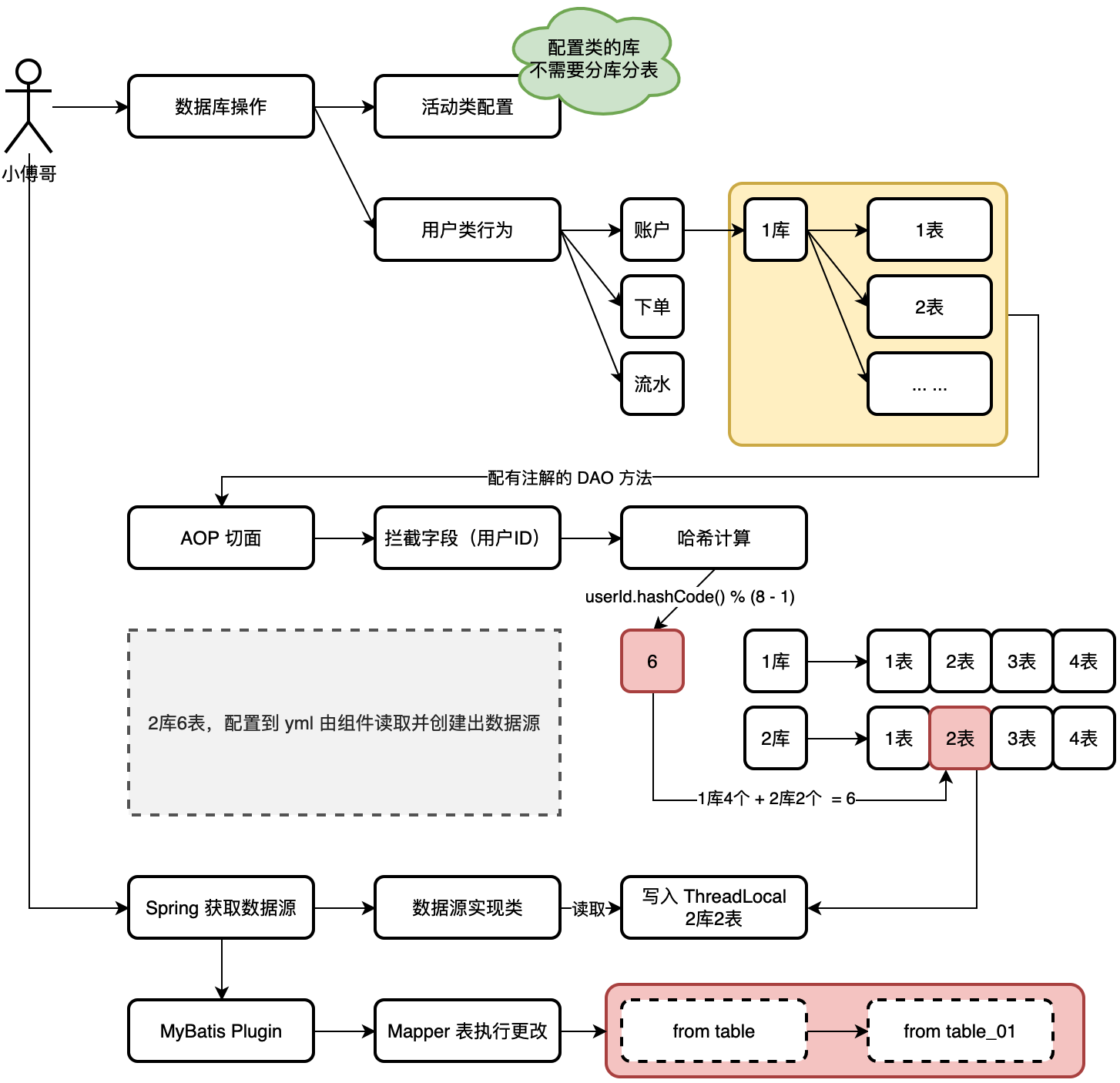
+我发现,其实不少伙伴并不具有分布式架构开发的经验,而学生👩🏻🎓不懂也是在所难免的,但那些`死鬼面试官`管你是不是学生,只要有卷王在,那就拔尖面。还有一部分伙伴一直在公司做 ERP、做B端的,就是业务流程,长、长、长、长、长,但核心技术基本没咋使用。
+
+
+

+
+

+
+

+
+
+
+
+
+
+
+

+
+

+
+
+
+

+