Jobs Service
IMPORTANT: This Kogito wiki is deprecated. For the latest Kogito documentation, see the Kogito documentation page. To contribute to Kogito documentation, see the
master-kogitobranch of thekie-docsrepository in GitHub.
Kogito Jobs Service is a dedicated lightweight service responsible for scheduling jobs that aim to be fired at a given time. The service does not execute the job itself, it triggers a callback that could be an HTTP request on a given endpoint specified on the job request, or any other callback that could be supported by the service.
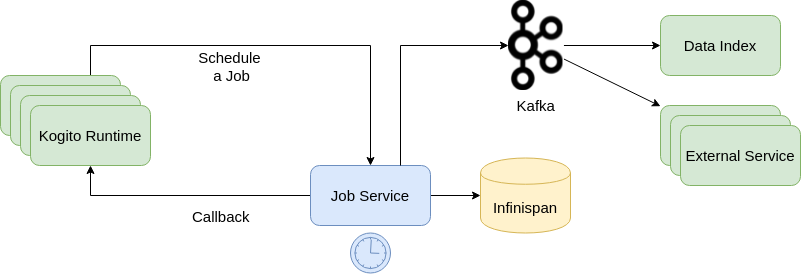
Basically, the Jobs Service receives requests of job scheduling and it sends a request at the time specified on the job request, as shown above.
The main goal of the service is to work with only active jobs, in this way it only keeps track of the jobs that are scheduled and supposed to be executed, the jobs that achieve a final state are removed from the job service. It is important to notice that all job information and transitioning states are pushed to Kogito Data Index where they can be indexed and made available for queries.
The Jobs Service implementation is based on non-blocking APIs and reactive messaging on the top of Quarkus, which provides the most effective throughput and resource utilization. The current scheduling engine is implemented on the top of Vert.x and the external requests are built using a non-blocking HTTP client based on Vert.x.
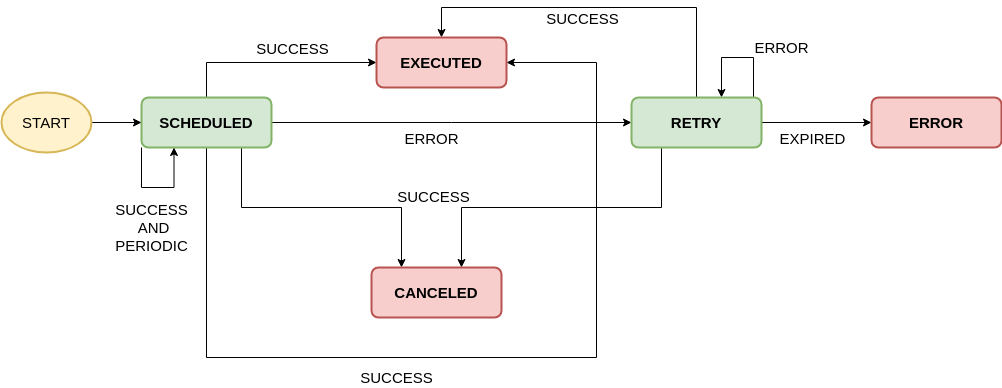
Jobs service uses an internal state control to manage the job scheduling lifecycle that is detailed on the following diagram:
Current these are the supported Job types that can be executed by the Jobs Service.
Jobs that are scheduled with a point in time and are executed only once when that point in time is reached. The time should be specified on the job scheduling request, and it should be in the future otherwise the job is not able to be scheduled.
The job is executed at a given point in time similar to the Time scheduled and if the execution is success, it triggers the job execution after a given interval and repeats this execution periodically until a limit of execution times is reached. The limit and interval should be specified on the Job scheduling request.
These are the supported callbacks that are fired when a job is executed. The callback information should be specified on the job scheduling request.
Uses an in-memory storage during the Job Service runtime, if the service is restarted all the information are lost. This is the default configuration of Job Service, so if no other configuration is set it will use this persistence mechanism.
Uses Infinispan as the storage, in this way Jobs Service can be restarted and it will continue to process any previous schedule job, since all the information is persisted on Infinispan. To enable this persistence it is necessary to set some configuration parameters, detailed on Infinispan Configuration
To enable Infinispan persistence it is quite simple, you should set the parameter kogito
.job-service.persistence=infinispan that could be set, either using -D option during the startup or setting it on the application.properties file present on the source code.
All Infinispan configuration like the servers address list, authentication, etc, follows Quarkus configuration mechanism and can be found here.
Jobs Service publish events for each job state transition to a topic, in this way any application could subscribe to this topic to receive information of jobs and the state it was transitioned. Inside Kogito architecture, Data-Index service is subscribed to the jobs topic, indexing the jobs with their current, in this way the all jobs can be fetched directly in the Data-Index.
The current supported message broker is Apache Kafka.
To enable Kafka messaging, you should use a specific Quarkus profile events-support that could be
set either using -D option during the startup -Dquarkus.profile=events-support or an environment
variable QUARKUS_PROFILE=events-support.
The Kafka bootstrap server can be set on the default Quarkus standard -Dmp.messaging.outgoing
.kogito-job-service-job-status-events.bootstrap.servers={server address}. Other configurations like the topic name,
can be set in the same way according to the Configuration properties.
The current API documentation is based on Swagger, and the service has an embedded UI available at http://localhost:8080/swagger-ui
Regardless of the runtime being used following are the configuration properties that can be set, otherwise the default values are going to be used.
Name |
Description |
Value |
Default |
kogito.jobs-service.persistence |
Identifies whe persistence mechanism used by the service. |
in-memory, infinispan |
in-memory |
kogito.jobs-service.backoffRetryMillis |
Retry backoff time in milliseconds between the job execution attempts, in case of execution failure. |
long |
1000 |
kogito.jobs-service.maxIntervalLimitToRetryMillis |
Maximum interval in milliseconds when retrying to execute jobs, in case of failures. |
long |
60000 |
mp.messaging.outgoing.kogito-job-service-job-status-events.bootstrap.servers |
Kafka bootstrap servers address with the port used to publish events |
string |
localhost:9092 |
mp.messaging.outgoing.kogito-job-service-job-status-events.topic |
Topic name where the events will be published |
string |
kogito-jobs-events |
-
Running
-
Using dev mode :
-
mvn clean compile quarkus:dev
-
Comand line based on the JAR file
java -jar jobs-service-8.0.0-SNAPSHOT-runner.jar
-
Running with Infinispan persistence
-
Using dev mode :
-
mvn clean compile quarkus:dev -Dkogito.jobs-service.persistence=infinispan
-
Comand line based on the JAR file
java -Dkogito.jobs-service.persistence=infinispan -jar jobs-service-8.0.0-SNAPSHOT-runner.jar
The basic actions on Job Service are made through REST as follow:
POST
{
"id": "1",
"priority": "1",
"expirationTime": "2019-11-29T18:16:00Z",
"callbackEndpoint": "http://localhost:8080/callback"
}Example:
curl -X POST \
http://localhost:8080/jobs/ \
-H 'Content-Type: application/json' \
-d '{
"id": "1",
"priority": "1",
"expirationTime": "2019-11-29T18:16:00Z",
"callbackEndpoint": "http://localhost:8080/callback"
}'
POST
{
"id": "1",
"priority": "1",
"expirationTime": "2019-11-29T18:19:00Z",
"callbackEndpoint": "http://localhost:8080/callback"
}Example:
curl -X POST \
http://localhost:8080/jobs/ \
-H 'Content-Type: application/json' \
-d '{
"id": "1",
"priority": "1",
"expirationTime": "2019-11-29T18:19:00Z",
"callbackEndpoint": "http://localhost:8080/callback"
}'
DELETE
Example:
curl -X DELETE http://localhost:8080/jobs/1
GET
Example:
curl -X GET http://localhost:8080/jobs/1
Addons are specific classes that provides integration with Kogito Job Service to the runtime services. This allows to use Job Service as a timer service for process instances. Whenever there is a need to schedule timer as part of process instance it will be scheduled in the Job Service and the job service will callback the service upon timer expiration.
The general implementation of the add-on is as follows:
-
an implementation of
org.kie.kogito.jobs.JobsServiceinterface that is used by the service to schedule jobs -
REST endpoint registered on
/management/jobspath
Regardless of the runtime being used following are two configuration properties that are expected (and by that are mandatory)
| Name | Description | Example |
|---|---|---|
|
A URL that identifies where the service is deployed to. Used by runtime events to set the source of the event. |
|
|
An URL that posts to a running Kogito Job Service, it is expected to be in form |
A dedicated org.kie.kogito.jobs.JobsService implementation is provided based on the runtime being used (either Quarkus or SpringBoot) as it relies on the technology used in these runtime to optimise dependencies and integration.
For Quarkus based runtimes, there is org.kie.kogito.jobs.management.quarkus.VertxJobsService implementation that utilises Vert.x WebClient to interact with Job Service over HTTP.
It configures web client by default based on properties found in application.properties.
Though in case this is not enough it supports to provide custom instance of io.vertx.ext.web.client.WebClient type that will be used instead to communicate with Job Service.
For Spring Boot based runtimes, there is org.kie.kogito.jobs.management.springboot.SpringRestJobsService implementation that utilises Spring RestTemplate to interact with Job Service over HTTP.
It configures rest template by default based on properties found in application.properties.
Though in case this is not enough it supports to provide custom instance of org.springframework.web.client.RestTemplate type that will be used instead to communicate with Job Service.
The REST endpoint that is provided with the add-on is responsible for receiving the callbacks from Job Service at exact time when the timer was scheduled and by that move the process instance execution forward.
The callback URL is given to the Job Service upon scheduling and as such does provide all the information that are required to move the instance
-
process id
-
process instance id
-
timer instance id
|
Note
|
Timer instance id is build out of two parts - actual job id (in UUID format) and a timer id (a timer definition id generated by the process engine).
An example of a timer instance id is 62cad2e4-d343-46ac-a89c-3e313a30c1ad_1 where 62cad2e4-d343-46ac-a89c-3e313a30c1ad is the UUID of the job and 1 is the timer definition id.
Both values are separated with _
|