TRNLTK version 1.0.2 is released.
With this release, a(nother) morphologic parser is provided. TRNLTK parser(TP for short) behaves quite different than Zemberek3 parser. Like Zemberek3 parser, TP is only a morphologic parser. It does not do disambiguation (for that please have a look at the disambiguation process in Zemberek3).
TRNTLK parser (TP for short) supports pluggable suffix graphs. There are multiple small graphs which are the computer representation of Turkish morphotactics and you can choose which ones you want to use. You can also modify existing graphs or implement your own graph. SuffixGraph is the interface to have a look:

For example, if you are worried about the number of results generated by big graphs, you can use smaller graphs. Graphs decorate each other. e.g.:
// small graph
SuffixGraph suffixGraph = new NumeralSuffixGraph(new BasicSuffixGraph());// big graph
SuffixGraph suffixGraph = new CopulaSuffixGraph(new ProperNounSuffixGraph(new NumeralSuffixGraph(new BasicSuffixGraph())));TBD(ali): separate visualizations of the graphs
TP supports pluggable root finders. That means, you can define the roots of "input"s to go through the suffix graph. This is helpful for example if you would like to recognize root of input "7-8'de" as "7-8" with category "Number Range". Here are some bundled root finders:
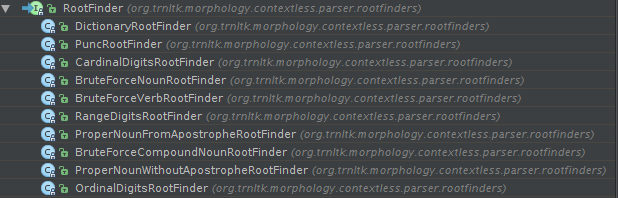
TP has a very consistent dictionary. Whole dictionary is reviewed manually.
TP has brute force methods bundled for unknown words or proper nouns. Please see the screenshots of the example web application.
TP is able to parse 99% of the words (morphologically correct words) and 95% of these words are parsed correctly. What is meant by "correct" is, it gives the correct morphologic parse as one of the parses it offers. The rest is to be done with disambiguation processes.
It would be fair to say that TRNLTK parser is really robust, dynamic and customizable(thanks to pluggable features). However, this causes a steeper learning curve. The code and thus the product is more abstract than Zemberek but less hacky.
Bundled suffix graphs and root finders covers almost all of Turkish morphology, but this has a price. It produces too many results compared to Zemberek parser. TP is very slow compared to Zemberek parser: 1250 token/sec vs 20000 token/sec. Even though with a smart caching and multithreading performance difference gets really smaller (30000 token/sec vs 80000 token/sec), there is so much to do in that area. It depends on your purpose, but this might be alright for now; can parse 1 billion word corpus in ~9 hours. From this perspective, Zemberek parser would be a better fit in case of memory and cpu limitations (ie. spell checking in word processors).
Here is a sample Maven pom.xml to use TRNLTK parser:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>trnltk-example</groupId>
<artifactId>trnltk-example</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.trnltk</groupId>
<artifactId>core</artifactId>
<version>1.0.2</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>trnltk-repo</id>
<url>http://trnltk-repo.googlecode.com/svn/maven/repo</url>
</repository>
<repository>
<id>google-diff-patch-match</id>
<name>google-diff-patch-match</name>
<url>http://google-diff-match-patch.googlecode.com/svn/trunk/maven/</url>
</repository>
</repositories>
</project>/**
* A simple example to demonstrate TRNLTK morhpologic parser.
* <p/>
* This example is a very simple one: parses very simple words only.
*/
public class SimpleExample {
public static void main(String[] args) {
ContextlessMorphologicParser parser = createParser();
String input = "eti";
List<MorphemeContainer> morphemeContainers = parser.parseStr(input);
System.out.println("Results for input \"" + input + "\":");
for (MorphemeContainer morphemeContainer : morphemeContainers) {
System.out.println("\t" + Formatter.formatMorphemeContainerWithForms(morphemeContainer));
}
}
private static ContextlessMorphologicParser createParser() {
// create common phonetic and morphotactic parts
PhoneticsAnalyzer phoneticsAnalyzer = new PhoneticsAnalyzer();
PhoneticAttributeSets phoneticAttributeSets = new PhoneticAttributeSets();
SuffixFormSequenceApplier suffixFormSequenceApplier = new SuffixFormSequenceApplier();
PhoneticsEngine phoneticsEngine = new PhoneticsEngine(suffixFormSequenceApplier);
SuffixApplier suffixApplier = new SuffixApplier(phoneticsEngine);
// create the suffix graph. the simplest one for now
BasicSuffixGraph suffixGraph = new BasicSuffixGraph();
suffixGraph.initialize();
// following is to extract a form-based graph from a suffix-based graph
SuffixFormGraphExtractor graphExtractor = new SuffixFormGraphExtractor(suffixFormSequenceApplier, phoneticsAnalyzer, phoneticAttributeSets);
// extract the formBasedGraph
SuffixFormGraph formBasedGraph = graphExtractor.extract(suffixGraph);
// create root entries from bundled dictionary
HashMultimap<String, ? extends Root> rootMap = RootMapFactory.createSimple();
// create chained root finders
RootFinderChain rootFinderChain = new RootFinderChain();
rootFinderChain.offer(new DictionaryRootFinder(rootMap), RootFinderChain.RootFinderPolicy.STOP_CHAIN_WHEN_INPUT_IS_HANDLED);
// create predefined paths
PredefinedPaths predefinedPaths = new PredefinedPaths(suffixGraph, rootMap, suffixApplier);
predefinedPaths.initialize();
// make sure you import org.trnltk.morphology.contextless.parser.ContextlessMorphologicParser
return new ContextlessMorphologicParser(formBasedGraph, predefinedPaths, rootFinderChain, suffixApplier);
}
}I will not go into details of the method createParser. Here is the result:
Results for input "eti":
et(et)+Noun+A3sg+Pnon+Acc(+yI[i])
et(et)+Noun+A3sg+P3sg(+sI[i])+Nom
A complex example: this time, a big graph and a lot of root finders are used to parse more complex words:
/**
* A complex example for TRNLTK parser.
* <p/>
* Parses numbers, proper nouns with apostrophe, words with hidden copula, words with improper circumflexes, ...
* Does not parse, unknown words (ie. does not go with the brute force method)
*/
public class ComplexExample {
public static void main(String[] args) {
ContextlessMorphologicParser parser = createParser();
parseInputAndPrintResults(parser, "yedi", true);
parseInputAndPrintResults(parser, "yüzdü", true);
parseInputAndPrintResults(parser, "7", true);
parseInputAndPrintResults(parser, "Ahmet'i",false);
parseInputAndPrintResults(parser, "TBMM'yi", false);
parseInputAndPrintResults(parser, "3-5", false);
parseInputAndPrintResults(parser, "3.'ye", false);
parseInputAndPrintResults(parser, "!..", false);
parseInputAndPrintResults(parser, "yapıverebilecekleriyken", false);
}
private static void parseInputAndPrintResults(ContextlessMorphologicParser parser, String input, boolean printSuffixForms) {
List<MorphemeContainer> morphemeContainers = parser.parseStr(input);
System.out.println("Results for input \"" + input + "\":");
for (MorphemeContainer morphemeContainer : morphemeContainers) {
if(printSuffixForms)
System.out.println("\t" + Formatter.formatMorphemeContainerWithForms(morphemeContainer));
else
System.out.println("\t" + Formatter.formatMorphemeContainer(morphemeContainer));
}
System.out.println();
}
private static ContextlessMorphologicParser createParser() {
// create common phonetic and morphotactic parts
PhoneticsAnalyzer phoneticsAnalyzer = new PhoneticsAnalyzer();
PhoneticAttributeSets phoneticAttributeSets = new PhoneticAttributeSets();
SuffixFormSequenceApplier suffixFormSequenceApplier = new SuffixFormSequenceApplier();
PhoneticsEngine phoneticsEngine = new PhoneticsEngine(suffixFormSequenceApplier);
SuffixApplier suffixApplier = new SuffixApplier(phoneticsEngine);
// cover all kind of morphotactic rules
CopulaSuffixGraph suffixGraph = new CopulaSuffixGraph(new ProperNounSuffixGraph(new NumeralSuffixGraph(new BasicSuffixGraph())));
suffixGraph.initialize();
// following is to extract a form-based graph from a suffix-based graph
SuffixFormGraphExtractor graphExtractor = new SuffixFormGraphExtractor(suffixFormSequenceApplier, phoneticsAnalyzer, phoneticAttributeSets);
// extract the formBasedGraph
SuffixFormGraph formBasedGraph = graphExtractor.extract(suffixGraph);
// create root entries from bundled dictionary
HashMultimap<String, ? extends Root> rootMap = RootMapFactory.createSimple();
// create chained root finders
DictionaryRootFinder dictionaryRootFinder = new DictionaryRootFinder(rootMap);
RangeDigitsRootFinder rangeDigitsRootFinder = new RangeDigitsRootFinder();
OrdinalDigitsRootFinder ordinalDigitsRootFinder = new OrdinalDigitsRootFinder();
CardinalDigitsRootFinder cardinalDigitsRootFinder = new CardinalDigitsRootFinder();
ProperNounFromApostropheRootFinder properNounFromApostropheRootFinder = new ProperNounFromApostropheRootFinder();
ProperNounWithoutApostropheRootFinder properNounWithoutApostropheRootFinder = new ProperNounWithoutApostropheRootFinder();
PuncRootFinder puncRootFinder = new PuncRootFinder();
final RootFinderChain rootFinderChain = new RootFinderChain()
.offer(puncRootFinder, RootFinderChain.RootFinderPolicy.STOP_CHAIN_WHEN_INPUT_IS_HANDLED)
.offer(rangeDigitsRootFinder, RootFinderChain.RootFinderPolicy.STOP_CHAIN_WHEN_INPUT_IS_HANDLED)
.offer(ordinalDigitsRootFinder, RootFinderChain.RootFinderPolicy.STOP_CHAIN_WHEN_INPUT_IS_HANDLED)
.offer(cardinalDigitsRootFinder, RootFinderChain.RootFinderPolicy.STOP_CHAIN_WHEN_INPUT_IS_HANDLED)
.offer(properNounFromApostropheRootFinder, RootFinderChain.RootFinderPolicy.STOP_CHAIN_WHEN_INPUT_IS_HANDLED)
.offer(properNounWithoutApostropheRootFinder, RootFinderChain.RootFinderPolicy.CONTINUE_ON_CHAIN)
.offer(dictionaryRootFinder, RootFinderChain.RootFinderPolicy.CONTINUE_ON_CHAIN);
// create predefined paths
PredefinedPaths predefinedPaths = new PredefinedPaths(suffixGraph, rootMap, suffixApplier);
predefinedPaths.initialize();
// make sure you import org.trnltk.morphology.contextless.parser.ContextlessMorphologicParser
return new ContextlessMorphologicParser(formBasedGraph, predefinedPaths, rootFinderChain, suffixApplier);
}
}Results for input "yedi":
ye(yemek)+Verb+Pos+Past(dI[di])+A3sg
Results for input "yüzdü":
yüz(yüzmek)+Verb+Pos+Past(dI[dü])+A3sg
yüz(yüz)+Noun+A3sg+Pnon+Nom+Verb+Zero+Past(+ydI[dü])+A3sg
Results for input "7":
7(7)+Num+DigitsC+Adj+Zero
7(7)+Num+DigitsC+Adj+Zero+Adv+Zero
7(7)+Num+DigitsC+Adj+Zero+Verb+Zero+Pres+A3sg
7(7)+Num+DigitsC+Adj+Zero+Noun+Zero+A3sg+Pnon+Nom
7(7)+Num+DigitsC+Adj+Zero+Adv+Zero+Verb+Zero+Pres+A3sg
7(7)+Num+DigitsC+Adj+Zero+Noun+Zero+A3sg+Pnon+Nom+Verb+Zero+Pres+A3sg
Results for input "Ahmet'i":
Ahmet+Noun+ProperNoun+Apos+A3sg+P3sg+Nom
Ahmet+Noun+ProperNoun+Apos+A3sg+Pnon+Acc
Ahmet+Noun+ProperNoun+Apos+A3sg+P3sg+Nom+Verb+Zero+Pres+A3sg
Ahmet+Noun+ProperNoun+Apos+A3sg+Pnon+Acc+Verb+Zero+Pres+A3sg
Results for input "TBMM'yi":
TBMM+Noun+ABBREVIATION+Apos+A3sg+Pnon+Acc
TBMM+Noun+ABBREVIATION+Apos+A3sg+Pnon+Acc+Verb+Zero+Pres+A3sg
Results for input "3-5":
3-5+Num+Range+Adj+Zero
3-5+Num+Range+Adj+Zero+Adv+Zero
3-5+Num+Range+Adj+Zero+Verb+Zero+Pres+A3sg
3-5+Num+Range+Adj+Zero+Noun+Zero+A3sg+Pnon+Nom
3-5+Num+Range+Adj+Zero+Adv+Zero+Verb+Zero+Pres+A3sg
3-5+Num+Range+Adj+Zero+Noun+Zero+A3sg+Pnon+Nom+Verb+Zero+Pres+A3sg
Results for input "3.'ye":
3.+Num+ORDINAL_DIGITS+Apos+Adj+Zero+Noun+Zero+A3sg+Pnon+Dat
3.+Num+ORDINAL_DIGITS+Apos+Adj+Zero+Noun+Zero+A3sg+Pnon+Dat+Verb+Zero+Pres+A3sg
Results for input "!..":
!..+Punc
Results for input "yapıverebilecekleriyken":
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Adj+FutPart+P3pl+Verb+Zero+Adv+While
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Noun+FutPart+A3sg+P3pl+Nom+Verb+Zero+Adv+While
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Noun+FutPart+A3pl+P3pl+Nom+Verb+Zero+Adv+While
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Noun+FutPart+A3pl+P3sg+Nom+Verb+Zero+Adv+While
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Noun+FutPart+A3pl+Pnon+Acc+Verb+Zero+Adv+While
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Adj+FutPart+P3pl+Verb+Zero+Adv+While+Verb+Zero+Pres+A3sg
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Fut+Adj+Zero+Noun+Zero+A3sg+P3pl+Nom+Verb+Zero+Adv+While
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Fut+Adj+Zero+Noun+Zero+A3pl+P3pl+Nom+Verb+Zero+Adv+While
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Fut+Adj+Zero+Noun+Zero+A3pl+P3sg+Nom+Verb+Zero+Adv+While
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Fut+Adj+Zero+Noun+Zero+A3pl+Pnon+Acc+Verb+Zero+Adv+While
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Noun+FutPart+A3sg+P3pl+Nom+Verb+Zero+Adv+While+Verb+Zero+Pres+A3sg
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Noun+FutPart+A3pl+P3pl+Nom+Verb+Zero+Adv+While+Verb+Zero+Pres+A3sg
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Noun+FutPart+A3pl+P3sg+Nom+Verb+Zero+Adv+While+Verb+Zero+Pres+A3sg
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Noun+FutPart+A3pl+Pnon+Acc+Verb+Zero+Adv+While+Verb+Zero+Pres+A3sg
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Fut+Adj+Zero+Noun+Zero+A3sg+P3pl+Nom+Verb+Zero+Adv+While+Verb+Zero+Pres+A3sg
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Fut+Adj+Zero+Noun+Zero+A3pl+P3pl+Nom+Verb+Zero+Adv+While+Verb+Zero+Pres+A3sg
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Fut+Adj+Zero+Noun+Zero+A3pl+P3sg+Nom+Verb+Zero+Adv+While+Verb+Zero+Pres+A3sg
yap+Verb+Pos+Verb+Hastily+Verb+Able+Pos+Fut+Adj+Zero+Noun+Zero+A3pl+Pnon+Acc+Verb+Zero+Adv+While+Verb+Zero+Pres+A3sg
You can the find the examples above (here)[https://sites.google.com/a/aliok.com.tr/upload/uploads/trnltk-sample.tar.gz?attredirects=0&d=1]
TRNLTK ships a web application to play with the parser. You can choose the suffix graphs and the root finders you like. You can also experiment with other customizable features of TP.
Please see how customization changes parse results.


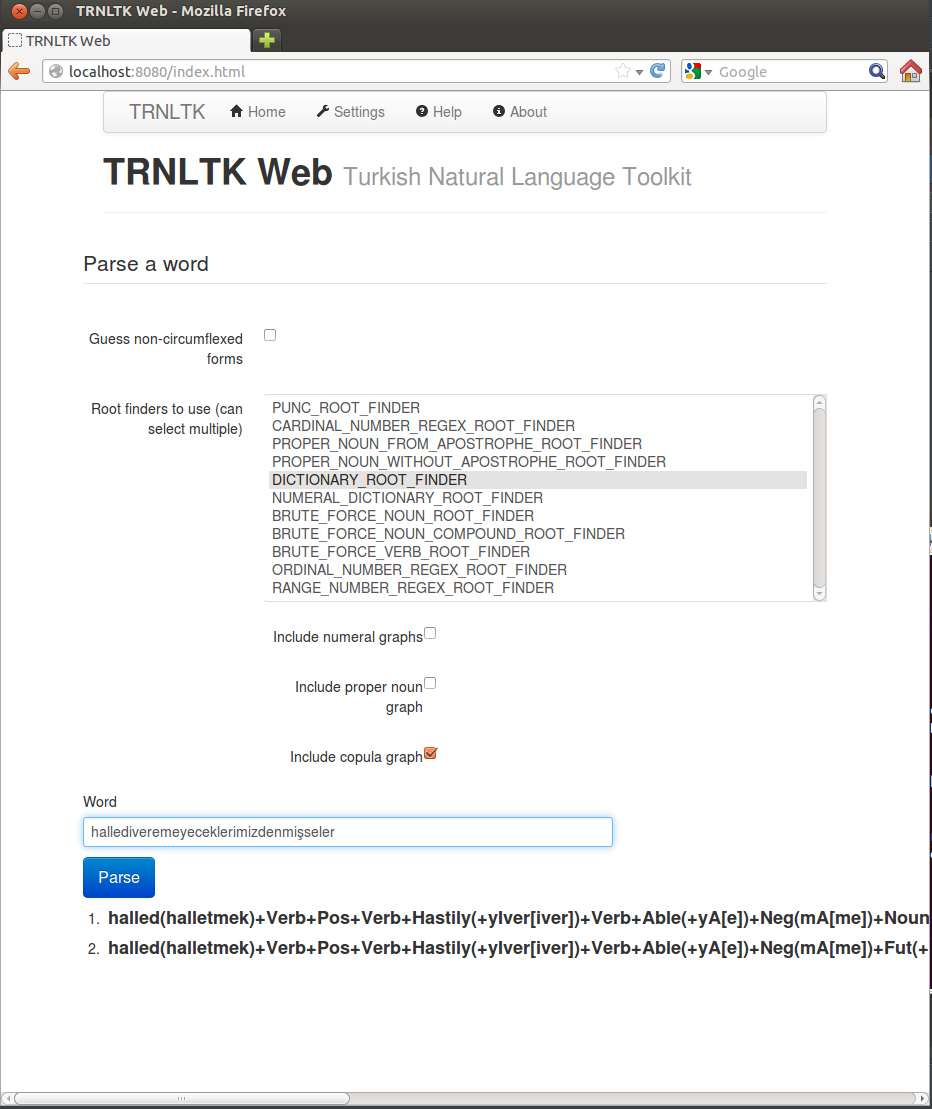

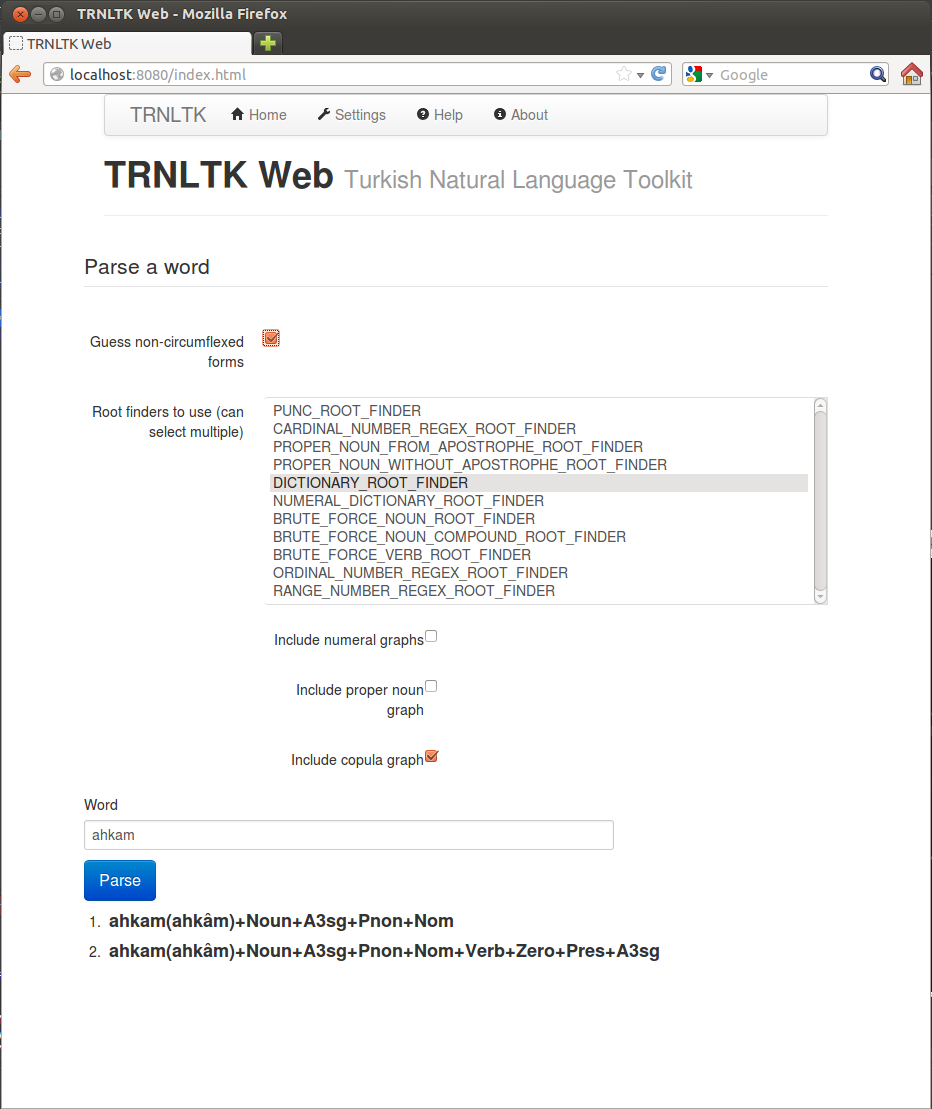

Web application is published at [zemberek-repo.googlecode.com/svn/maven/repo/org/trnltk/web/1.0.0/web-1.0.0.war zemberek-repo.googlecode.com/svn/maven/repo/org/trnltk/web/1.0.0/web-1.0.0.war]
It includes all dependencies and is ready to run. Just deploy into your application server e.g. Tomcat.
The other option (easier option if you don't have an application server already) is checking out the code and issuing the command mvn :
- Check out TRNLTK branch
release1_0_2:
For GIT >= 1.7.10 ( (reason)[https://lkml.org/lkml/2012/3/28/418])) :
> git clone -b release1_0_2 --single-branch https://github.com/aliok/trnltk-java.gitFor GIT < 1.7.10 :
> git clone https://github.com/aliok/trnltk-java.git
Cloning into 'trnltk-java'...
remote: Counting objects: 13228, done.
remote: Finding sources: 100% (13228/13228), done.
remote: Total 13228 (delta 5282)
Receiving objects: 100% (13228/13228), 25.10 MiB | 1.21 MiB/s, done.
Resolving deltas: 100% (5282/5282), done.
> cd trnltk-java
> git checkout --track origin/release1_0_2
Branch release1_0_2 set up to track remote branch release1_0_2 from origin.
Switched to a new branch 'release1_0_2'- Navigate to
webmodule :
> cd web/- Issue
mvn:
> mvn
...
[INFO] Started Jetty Server
[INFO] Starting scanner at interval of 10 seconds.