Benchmarks : Grouping
- The input data is randomly ordered. No pre-sort. No indexes. No key.
- 5 simple queries are run. Similar to what a data analyst might do in practice; i.e., various ad hoc aggregations as the data is explored and investigated.
- Each package is tested separately in its own fresh R session.
- Each query is repeated once more, immediately. This is to isolate cache effects and confirm the first timing. The first and second times are plotted. The total runtime is also displayed.
- The results are compared and checked allowing for numeric tolerance and column name differences.
Scroll to the bottom to find reproducible code and system info.
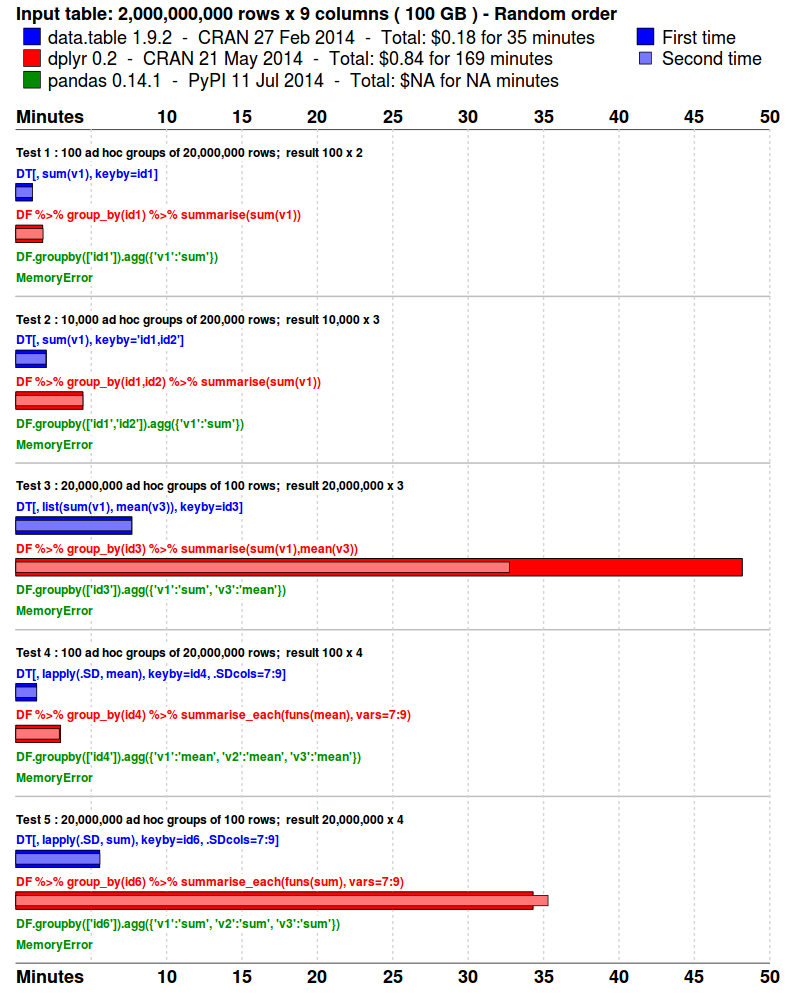
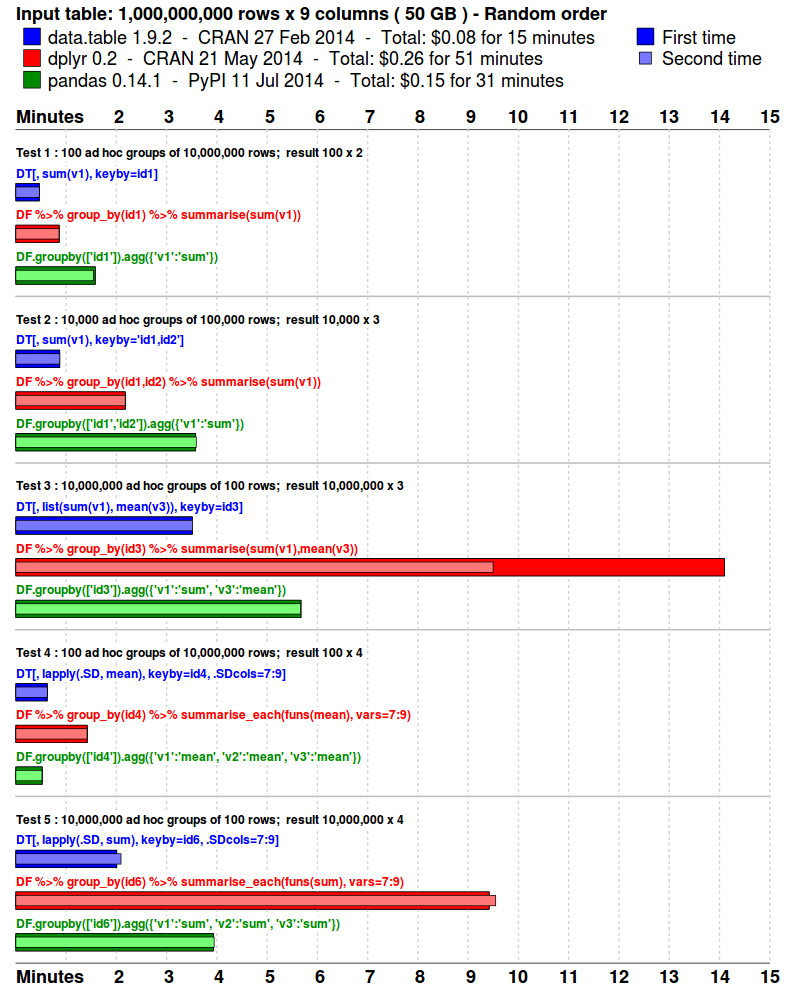
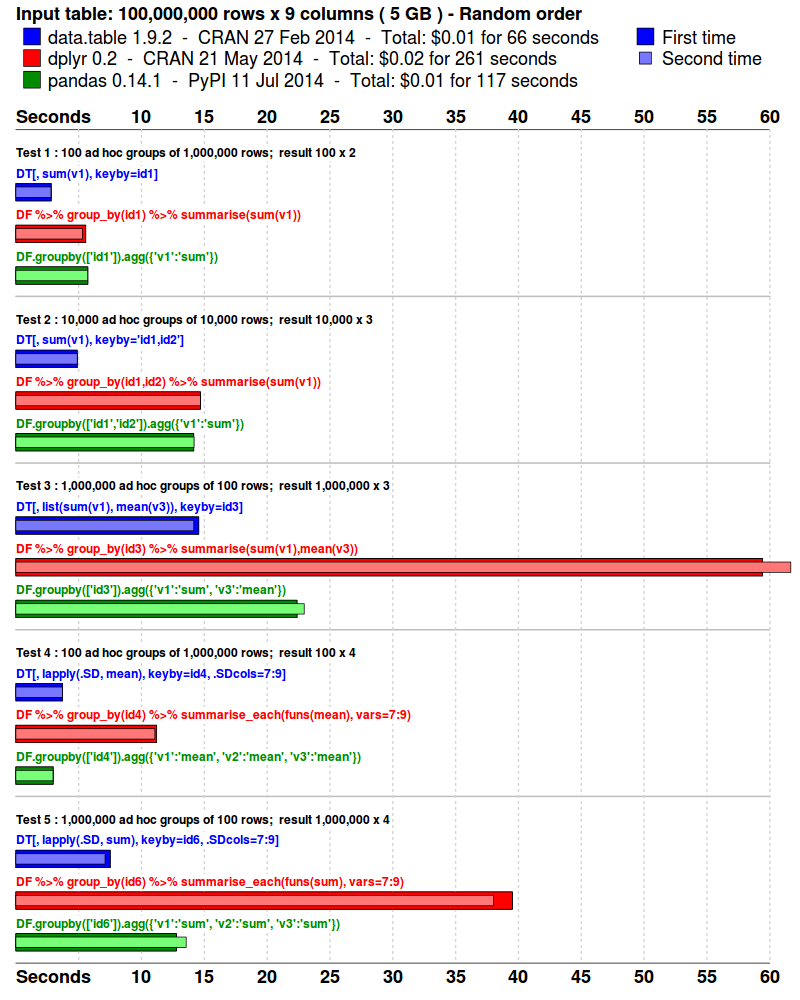

## data.table run
$ R --vanilla
require(data.table)
N=2e9; K=100
set.seed(1)
DT <- data.table(
id1 = sample(sprintf("id%03d",1:K), N, TRUE), # large groups (char)
id2 = sample(sprintf("id%03d",1:K), N, TRUE), # large groups (char)
id3 = sample(sprintf("id%010d",1:(N/K)), N, TRUE), # small groups (char)
id4 = sample(K, N, TRUE), # large groups (int)
id5 = sample(K, N, TRUE), # large groups (int)
id6 = sample(N/K, N, TRUE), # small groups (int)
v1 = sample(5, N, TRUE), # int in range [1,5]
v2 = sample(1e6, N, TRUE), # int in range [1,1e6]
v3 = sample(round(runif(100,max=100),4), N, TRUE) # numeric e.g. 23.5749
)
cat("GB =", round(sum(gc()[,2])/1024, 3), "\n")
system.time( DT[, sum(v1), keyby=id1] )
system.time( DT[, sum(v1), keyby=id1] )
system.time( DT[, sum(v1), keyby="id1,id2"] )
system.time( DT[, sum(v1), keyby="id1,id2"] )
system.time( DT[, list(sum(v1),mean(v3)), keyby=id3] )
system.time( DT[, list(sum(v1),mean(v3)), keyby=id3] )
system.time( DT[, lapply(.SD, mean), keyby=id4, .SDcols=7:9] )
system.time( DT[, lapply(.SD, mean), keyby=id4, .SDcols=7:9] )
system.time( DT[, lapply(.SD, sum), keyby=id6, .SDcols=7:9] )
system.time( DT[, lapply(.SD, sum), keyby=id6, .SDcols=7:9] )
## dplyr run
$ R --vanilla
require(dplyr)
N=2e9; K=100
set.seed(1)
DF <- data.frame(stringsAsFactors=FALSE,
id1 = sample(sprintf("id%03d",1:K), N, TRUE),
id2 = sample(sprintf("id%03d",1:K), N, TRUE),
id3 = sample(sprintf("id%010d",1:(N/K)), N, TRUE),
id4 = sample(K, N, TRUE),
id5 = sample(K, N, TRUE),
id6 = sample(N/K, N, TRUE),
v1 = sample(5, N, TRUE),
v2 = sample(1e6, N, TRUE),
v3 = sample(round(runif(100,max=100),4), N, TRUE)
)
cat("GB =", round(sum(gc()[,2])/1024, 3), "\n")
system.time( DF %>% group_by(id1) %>% summarise(sum(v1)) )
system.time( DF %>% group_by(id1) %>% summarise(sum(v1)) )
system.time( DF %>% group_by(id1,id2) %>% summarise(sum(v1)) )
system.time( DF %>% group_by(id1,id2) %>% summarise(sum(v1)) )
system.time( DF %>% group_by(id3) %>% summarise(sum(v1),mean(v3)) )
system.time( DF %>% group_by(id3) %>% summarise(sum(v1),mean(v3)) )
system.time( DF %>% group_by(id4) %>% summarise_each(funs(mean), vars=7:9) )
system.time( DF %>% group_by(id4) %>% summarise_each(funs(mean), vars=7:9) )
system.time( DF %>% group_by(id6) %>% summarise_each(funs(sum), vars=7:9) )
system.time( DF %>% group_by(id6) %>% summarise_each(funs(sum), vars=7:9) )$ R --vanilla
# R version 3.1.1 (2014-07-10) -- "Sock it to Me"
# Copyright (C) 2014 The R Foundation for Statistical Computing
# Platform: x86_64-pc-linux-gnu (64-bit)
> sessionInfo()
# R version 3.1.1 (2014-07-10)
# Platform: x86_64-pc-linux-gnu (64-bit)
#
# locale:
# [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
# [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
# [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
# [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
# [9] LC_ADDRESS=C LC_TELEPHONE=C
# [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
# attached base packages:
# [1] stats graphics grDevices utils datasets methods base
# other attached packages:
# [1] dplyr_0.2 data.table_1.9.2
#
# loaded via a namespace (and not attached):
# [1] assertthat_0.1 parallel_3.1.1 plyr_1.8.1 Rcpp_0.11.2 reshape2_1.4
# [6] stringr_0.6.2 tools_3.1.1$ lsb_release -a
# No LSB modules are available.
# Distributor ID: Ubuntu
# Description: Ubuntu 14.04 LTS
# Release: 14.04
# Codename: trusty
$ uname -a
# Linux ip-172-31-33-222 3.13.0-29-generic #53-Ubuntu SMP
# Wed Jun 4 21:00:20 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
$ lscpu
# Architecture: x86_64
# CPU op-mode(s): 32-bit, 64-bit
# Byte Order: Little Endian
# CPU(s): 32
# On-line CPU(s) list: 0-31
# Thread(s) per core: 2
# Core(s) per socket: 8
# Socket(s): 2
# NUMA node(s): 2
# Vendor ID: GenuineIntel
# CPU family: 6
# Model: 62
# Stepping: 4
# CPU MHz: 2494.090
# BogoMIPS: 5049.01
# Hypervisor vendor: Xen
# Virtualization type: full
# L1d cache: 32K
# L1i cache: 32K
# L2 cache: 256K
# L3 cache: 25600K
# NUMA node0 CPU(s): 0-7,16-23
# NUMA node1 CPU(s): 8-15,24-31
$ free -h
# total used free shared buffers cached
# Mem: 240G 2.4G 237G 364K 60M 780M
# -/+ buffers/cache: 1.6G 238G
# Swap: 0B 0B 0B